RAG Tools Introduction
**RAGTools has moved to a separate package since PromptingTools v0.75!** This documentation demonstrates the RAG ecosystem but all functionality is now in [RAGTools.jl](https://github.com/JuliaGenAI/RAGTools.jl). See our [Migration Guide](ragtools_migration.md) for details.
RAGTools provides a set of utilities for building Retrieval-Augmented Generation (RAG) applications - applications that generate answers by combining knowledge of the underlying AI model with information from your knowledge base.
The examples below showcase the powerful and flexible RAG ecosystem available in Julia. You can extend any step of the pipeline with your own custom code, or use the provided defaults to get started quickly.
Import the module as follows:
# Import the dedicated RAGTools package
using RAGTools
# For accessing unexported functionality
const RT = RAGToolsSince PromptingTools v0.75, RAGTools is a separate package. Install it with `using Pkg; Pkg.add("RAGTools")`. The API remains identical - only the import changes!
Highlights
The main functions to be aware of are:
build_indexto build a RAG index from a list of documents (typeChunkIndex)airagto generate answers using the RAG model on top of theindexbuilt aboveretrieveto retrieve relevant chunks from the index for a given questiongenerate!to generate an answer from the retrieved chunks
annotate_supportto highlight which parts of the RAG answer are supported by the documents in the index vs which are generated by the model, it is applied automatically if you use pretty printing withpprint(eg,pprint(result))build_qa_evalsto build a set of question-answer pairs for evaluation of the RAG model from your corpus
The hope is to provide a modular and easily extensible set of tools for building RAG applications in Julia. Feel free to open an issue or ask in the #generative-ai channel in the JuliaLang Slack if you have a specific need.
Examples
Let's build an index, we need to provide a starter list of documents:
sentences = [
"Find the most comprehensive guide on Julia programming language for beginners published in 2023.",
"Search for the latest advancements in quantum computing using Julia language.",
"How to implement machine learning algorithms in Julia with examples.",
"Looking for performance comparison between Julia, Python, and R for data analysis.",
"Find Julia language tutorials focusing on high-performance scientific computing.",
"Search for the top Julia language packages for data visualization and their documentation.",
"How to set up a Julia development environment on Windows 10.",
"Discover the best practices for parallel computing in Julia.",
"Search for case studies of large-scale data processing using Julia.",
"Find comprehensive resources for mastering metaprogramming in Julia.",
"Looking for articles on the advantages of using Julia for statistical modeling.",
"How to contribute to the Julia open-source community: A step-by-step guide.",
"Find the comparison of numerical accuracy between Julia and MATLAB.",
"Looking for the latest Julia language updates and their impact on AI research.",
"How to efficiently handle big data with Julia: Techniques and libraries.",
"Discover how Julia integrates with other programming languages and tools.",
"Search for Julia-based frameworks for developing web applications.",
"Find tutorials on creating interactive dashboards with Julia.",
"How to use Julia for natural language processing and text analysis.",
"Discover the role of Julia in the future of computational finance and econometrics."
]Let's index these "documents":
index = build_index(sentences; chunker_kwargs=(; sources=map(i -> "Doc$i", 1:length(sentences))))This would be equivalent to the following index = build_index(SimpleIndexer(), sentences) which dispatches to the default implementation of each step via the SimpleIndexer struct. We provide these default implementations for the main functions as an optional argument - no need to provide them if you're running the default pipeline.
Notice that we have provided a chunker_kwargs argument to the build_index function. These will be kwargs passed to chunker step.
Now let's generate an answer to a question.
- Run end-to-end RAG (retrieve + generate!), return
AIMessage
question = "What are the best practices for parallel computing in Julia?"
msg = airag(index; question) # short for airag(RAGConfig(), index; question)
## Output:
## [ Info: Done with RAG. Total cost: \$0.0
## AIMessage("Some best practices for parallel computing in Julia include us...- Explore what's happening under the hood by changing the return type -
RAGResultcontains all intermediate steps.
result = airag(index; question, return_all=true)
## RAGResult
## question: String "What are the best practices for parallel computing in Julia?"
## rephrased_questions: Array{String}((1,))
## answer: SubString{String}
## final_answer: SubString{String}
## context: Array{String}((5,))
## sources: Array{String}((5,))
## emb_candidates: CandidateChunks{Int64, Float32}
## tag_candidates: CandidateChunks{Int64, Float32}
## filtered_candidates: CandidateChunks{Int64, Float32}
## reranked_candidates: CandidateChunks{Int64, Float32}
## conversations: Dict{Symbol, Vector{<:PromptingTools.AbstractMessage}}You can still get the message from the result, see result.conversations[:final_answer] (the dictionary keys correspond to the function names of those steps).
- If you need to customize it, break the pipeline into its sub-steps: retrieve and generate - RAGResult serves as the intermediate result.
# Retrieve which chunks are relevant to the question
result = retrieve(index, question)
# Generate an answer
result = generate!(index, result)You can leverage a pretty-printing system with pprint where we automatically annotate the support of the answer by the chunks we provided to the model. It is configurable and you can select only some of its functions (eg, scores, sources).
pprint(result)You'll see the following in REPL but with COLOR highlighting in the terminal.
--------------------
QUESTION(s)
--------------------
- What are the best practices for parallel computing in Julia?
--------------------
ANSWER
--------------------
Some of the best practices for parallel computing in Julia include:[1,0.7]
- Using [3,0.4]`@threads` for simple parallelism[1,0.34]
- Utilizing `Distributed` module for more complex parallel tasks[1,0.19]
- Avoiding excessive memory allocation
- Considering task granularity for efficient workload distribution
--------------------
SOURCES
--------------------
1. Doc8
2. Doc15
3. Doc5
4. Doc2
5. Doc9See ?print_html for the HTML version of the pretty-printing and styling system, eg, when you want to display the results in a web application based on Genie.jl/Stipple.jl.
How to read the output
Color legend:
No color: High match with the context, can be trusted more
Blue: Partial match against some words in the context, investigate
Magenta (Red): No match with the context, fully generated by the model
Square brackets: The best matching context ID + Match score of the chunk (eg,
[3,0.4]means the highest support for the sentence is from the context chunk number 3 with a 40% match).
Want more?
See examples/building_RAG.jl for a comprehensive example. Note that examples now use using RAGTools instead of the experimental module.
**Migrating from PromptingTools.Experimental.RAGTools?** Check out our detailed [Migration Guide](ragtools_migration.md) with step-by-step instructions and examples.
RAG Interface
System Overview
This system is designed for information retrieval and response generation, structured in three main phases:
Preparation, when you create an instance of
AbstractIndexRetrieval, when you surface the top most relevant chunks/items in the
indexand returnAbstractRAGResult, which contains the references to the chunks (AbstractCandidateChunks)Generation, when you generate an answer based on the context built from the retrieved chunks, return either
AIMessageorAbstractRAGResult
The corresponding functions are build_index, retrieve, and generate!, respectively. Here is the high-level diagram that shows the signature of the main functions:
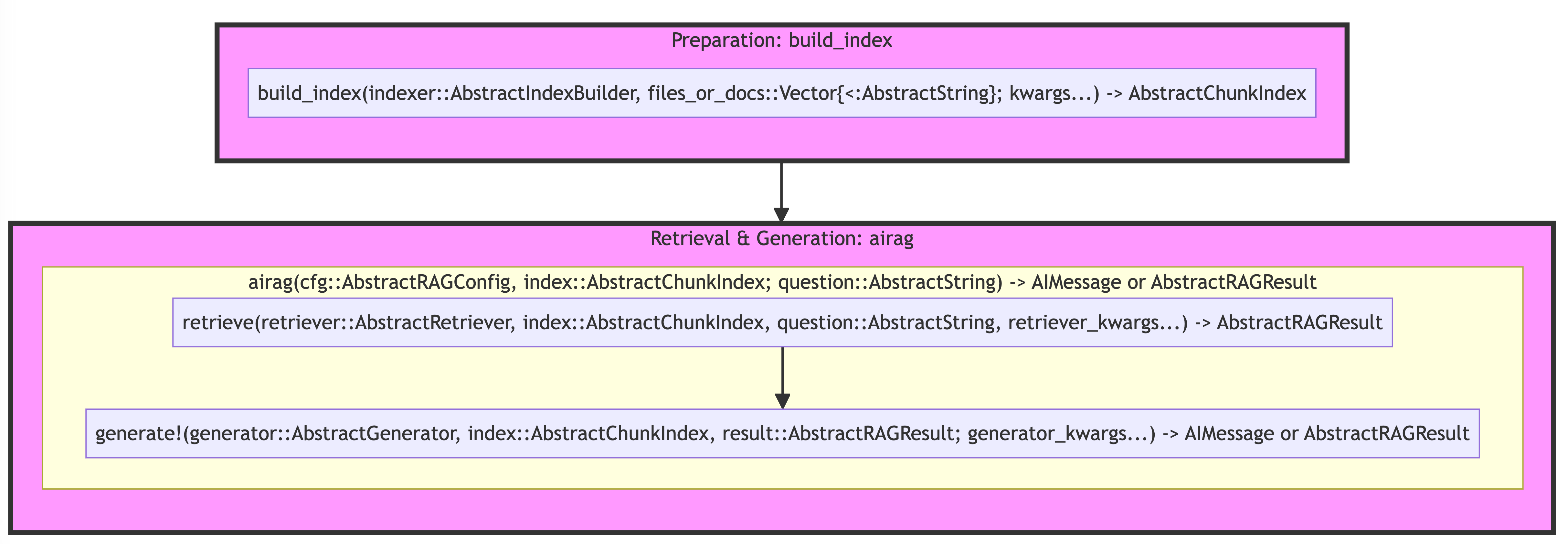
Notice that the first argument is a custom type for multiple dispatch. In addition, observe the "kwargs" names, that's how the keyword arguments for each function are passed down from the higher-level functions (eg, build_index(...; chunker_kwargs=(; separators=...)))). It's the simplest way to customize some step of the pipeline (eg, set a custom model with a model kwarg or prompt template with template kwarg).
The system is designed to be hackable and extensible at almost every entry point. If you want to customize the behavior of any step, you can do so by defining a new type and defining a new method for the step you're changing, eg,
PromptingTools.Experimental.RAGTools: rerank
struct MyReranker <: AbstractReranker end
rerank(::MyReranker, index, candidates) = ...And then you would set the retrive step to use your custom MyReranker via reranker kwarg, eg, retrieve(....; reranker = MyReranker()) (or customize the main dispatching AbstractRetriever struct).
The overarching principles are:
Always dispatch / customize the behavior by defining a new
Structand the corresponding method for the existing functions (eg,rerankfunction for the re-ranking step).Custom types are provided as the first argument (the high-level functions will work without them as we provide some defaults).
Custom types do NOT have any internal fields or DATA (with the exception of managing sub-steps of the pipeline like
AbstractRetrieverorRAGConfig).Additional data should be passed around as keyword arguments (eg,
chunker_kwargsinbuild_indexto pass data to the chunking step). The intention was to have some clearly documented default values in the docstrings of each step + to have the various options all in one place.
RAG Diagram
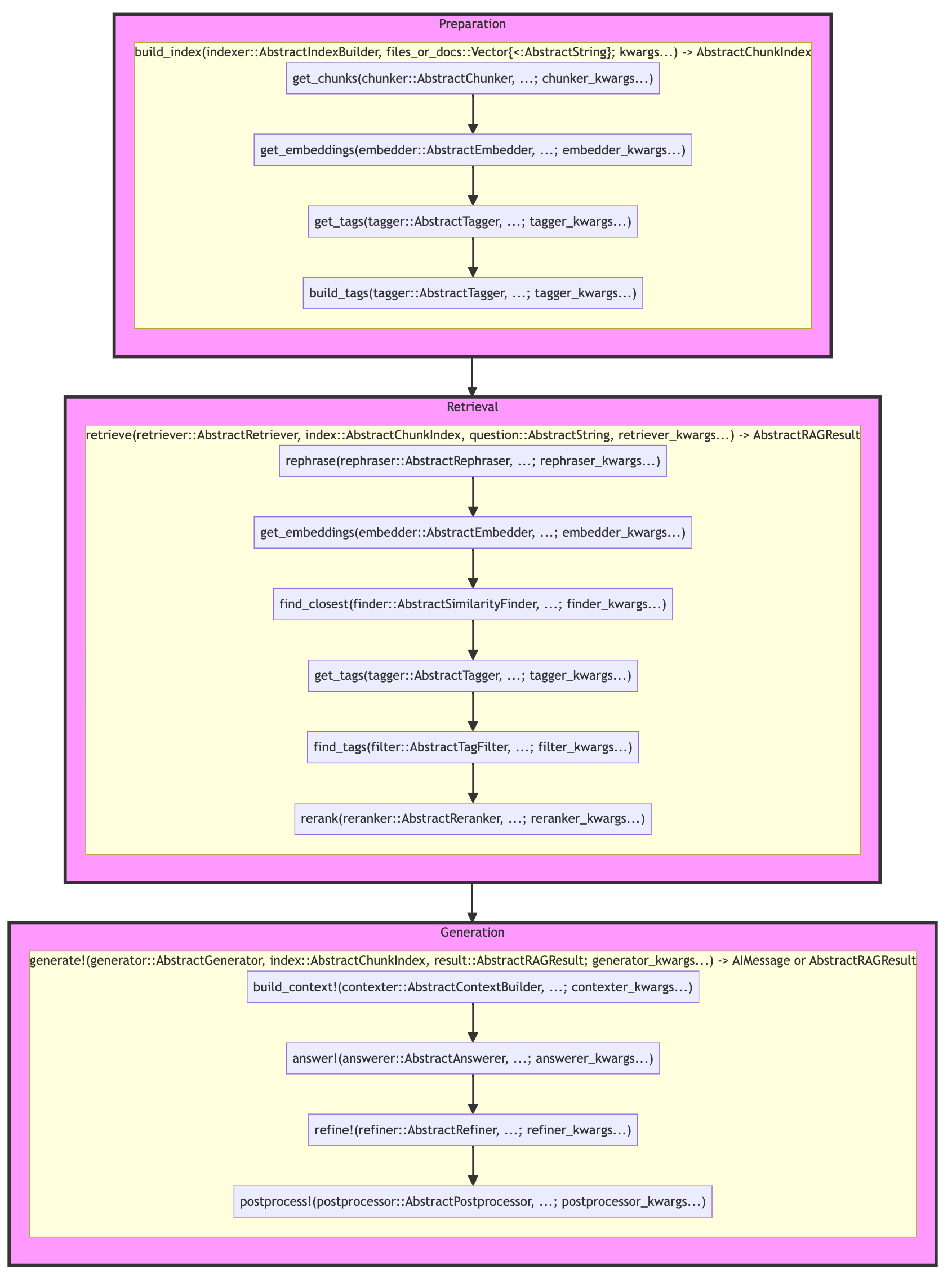
The main functions are:
Prepare your document index with build_index:
signature:
(indexer::AbstractIndexBuilder, files_or_docs::Vector{<:AbstractString}) -> AbstractChunkIndexflow:
get_chunks->get_embeddings->get_tags->build_tagsdispatch types:
AbstractIndexBuilder,AbstractChunker,AbstractEmbedder,AbstractTagger
Run E2E RAG with airag:
signature:
(cfg::AbstractRAGConfig, index::AbstractChunkIndex; question::AbstractString)->AIMessageorAbstractRAGResultflow:
retrieve->generate!dispatch types:
AbstractRAGConfig,AbstractRetriever,AbstractGenerator
Retrieve relevant chunks with retrieve:
signature:
(retriever::AbstractRetriever, index::AbstractChunkIndex, question::AbstractString) -> AbstractRAGResultflow:
rephrase->get_embeddings->find_closest->get_tags->find_tags->rerankdispatch types:
AbstractRAGConfig,AbstractRephraser,AbstractEmbedder,AbstractSimilarityFinder,AbstractTagger,AbstractTagFilter,AbstractReranker
Generate an answer from relevant chunks with generate!:
signature:
(generator::AbstractGenerator, index::AbstractChunkIndex, result::AbstractRAGResult)->AIMessageorAbstractRAGResultflow:
build_context!->answer!->refine!->postprocess!dispatch types:
AbstractGenerator,AbstractContextBuilder,AbstractAnswerer,AbstractRefiner,AbstractPostprocessor
To discover the currently available implementations, use subtypes function, eg, subtypes(AbstractReranker).
Passing Keyword Arguments
If you need to pass keyword arguments, use the nested kwargs corresponding to the dispatch type names (rephrase step, has rephraser dispatch type and rephraser_kwargs for its keyword arguments).
For example:
cfg = RAGConfig(; retriever = AdvancedRetriever())
# kwargs will be big and nested, let's prepare them upfront
# we specify "custom" model for each component that calls LLM
kwargs = (
retriever = AdvancedRetriever(),
retriever_kwargs = (;
top_k = 100,
top_n = 5,
# notice that this is effectively: retriever_kwargs/rephraser_kwargs/template
rephraser_kwargs = (;
template = :RAGQueryHyDE,
model = "custom")),
generator_kwargs = (;
# pass kwargs to `answer!` step defined by the `answerer` -> we're setting `answerer_kwargs`
answerer_kwargs = (;
model = "custom"),
# api_kwargs can be shared across all components
api_kwargs = (;
url = "http://localhost:8080")))
result = airag(cfg, index, question; kwargs...)If you were one level deeper in the pipeline, working with retriever directly, you would pass:
retriever_kwargs = (;
top_k = 100,
top_n = 5,
# notice that this is effectively: rephraser_kwargs/template
rephraser_kwargs = (;
template = :RAGQueryHyDE,
model = "custom"),
# api_kwargs can be shared across all components
api_kwargs = (;
url = "http://localhost:8080"))
result = retrieve(AdvancedRetriever(), index, question; retriever_kwargs...)And going even deeper, you would provide the rephraser_kwargs directly to the rephrase step, eg,
rephrase(SimpleRephraser(), question; model="custom", template = :RAGQueryHyDE, api_kwargs = (; url = "http://localhost:8080"))Deepdive
Preparation Phase:
Begins with
build_index, which creates a user-defined index type from an abstract chunk index using specified dels and function strategies.get_chunksthen divides the indexed data into manageable pieces based on a chunking strategy.get_embeddingsgenerates embeddings for each chunk using an embedding strategy to facilitate similarity arches.Finally,
get_tagsextracts relevant metadata from each chunk, enabling tag-based filtering (hybrid search index). If there aretagsavailable,build_tagsis called to build the corresponding sparse matrix for filtering with tags.
Retrieval Phase:
The
retrievestep is intended to find the most relevant chunks in theindex.rephraseis called first, if we want to rephrase the query (methods likeHyDEcan improve retrieval quite a bit)!get_embeddingsgenerates embeddings for the original + rephrased queryfind_closestlooks up the most relevant candidates (CandidateChunks) using a similarity search strategy.get_tagsextracts the potential tags (can be provided as part of theairagcall, eg, when we want to use only some small part of the indexed chunks)find_tagsfilters the candidates to strictly match at least one of the tags (if provided)rerankis called to rerank the candidates based on the reranking strategy (ie, to improve the ordering of the chunks in context).
Generation Phase:
The
generate!step is intended to generate a response based on the retrieved chunks, provided viaAbstractRAGResult(eg,RAGResult).build_context!constructs the context for response generation based on a context strategy and applies the necessary formattinganswer!generates the response based on the context and the queryrefine!is called to refine the response (optional, defaults to passthrough)postprocessing!is available for any final touches to the response or to potentially save or format the results (eg, automatically save to the disk)
Note that all generation steps are mutating the RAGResult object.
See more details and corresponding functions and types in src/Experimental/RAGTools/rag_interface.jl.