Is there an optimal temperature and top-p for code generation with paid LLM APIs?
TL;DR
After experimenting with various API parameters for OpenAI and MistralAI, I found that tweaking two settings—temperature and top_p—could boost code generation performance. But these AI models are like the weather in London; they change so often that today's "perfect" settings might be outdated by tomorrow. So, rather than chase the elusive 'perfect' setup, it's wiser to focus on creating robust tests for your AI's performance. Keep it simple and let the AI do the heavy lifting!
Last week, the buzz was all about MistralAI's new API launch, featuring the enigmatic "mistral-medium"—a tier that's not as widely discussed as the hyped "Mixtral 8x7B" ("mistral-small" on Mistral's La Plateforme). Curious, I took my Julia code generation benchmarks for a spin and noticed that "mistral-medium" wasn't significantly outperforming its smaller sibling.
Here's the catch: such results are only relevant to my mini benchmark and may not hold true across other domains. So, I pondered, could this be due to suboptimal hyperparameters? With that in mind, I decided to tinker with temperature and top_p—parameters that essentially control the creativity and focus of the AI's responses.
I needed a test dataset. Fortunately, there is a Julia-LLM-Leaderboard which has a collection of Julia code generation tasks with a corresponding automated evaluation framework. Each run can score between 0-100 points, where 100 points is the best.
My experiment was straightforward. I ran a grid search across 36 combinations of temperature and top_p values, refining the process until I found what seemed like "sweet spots." (detail here). I did the same for 3 OpenAI and 3 Mistral models.
Interestingly, mistral-medium's performance soared from 54 to 87 points by adjusting to top_p: 0.3 and temperature: 0.9.
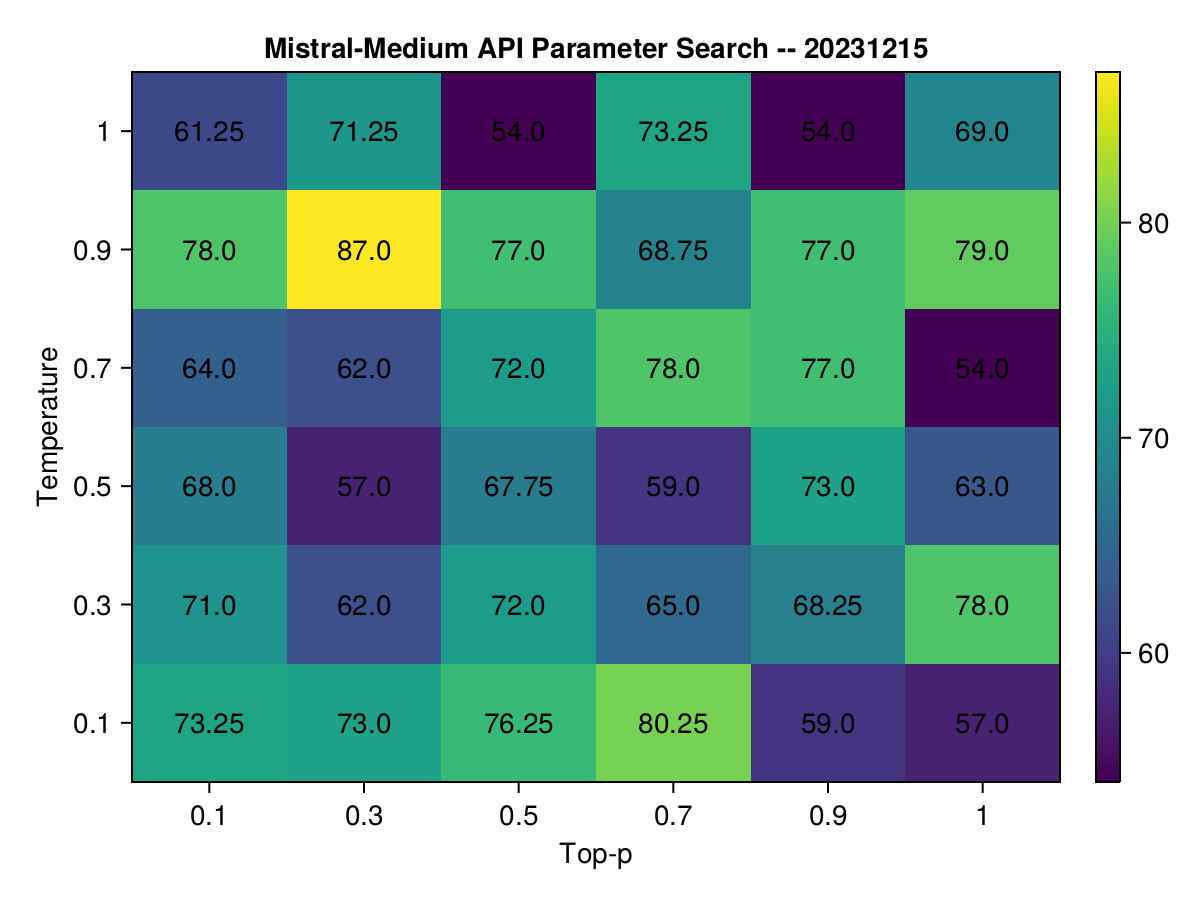
This has been after c. 200 runs (representing <20% of the available test cases). I decided to pick these as the new "optimal" parameters and re-run the full benchmark (I did the same for all other models as well).
But here's the twist—repeating the benchmark revealed no significant change. After a bit of sleuthing, I discovered the API's model had been updated, rendering my "optimal" parameters outdated.
See how the same heatmap looked one day later:
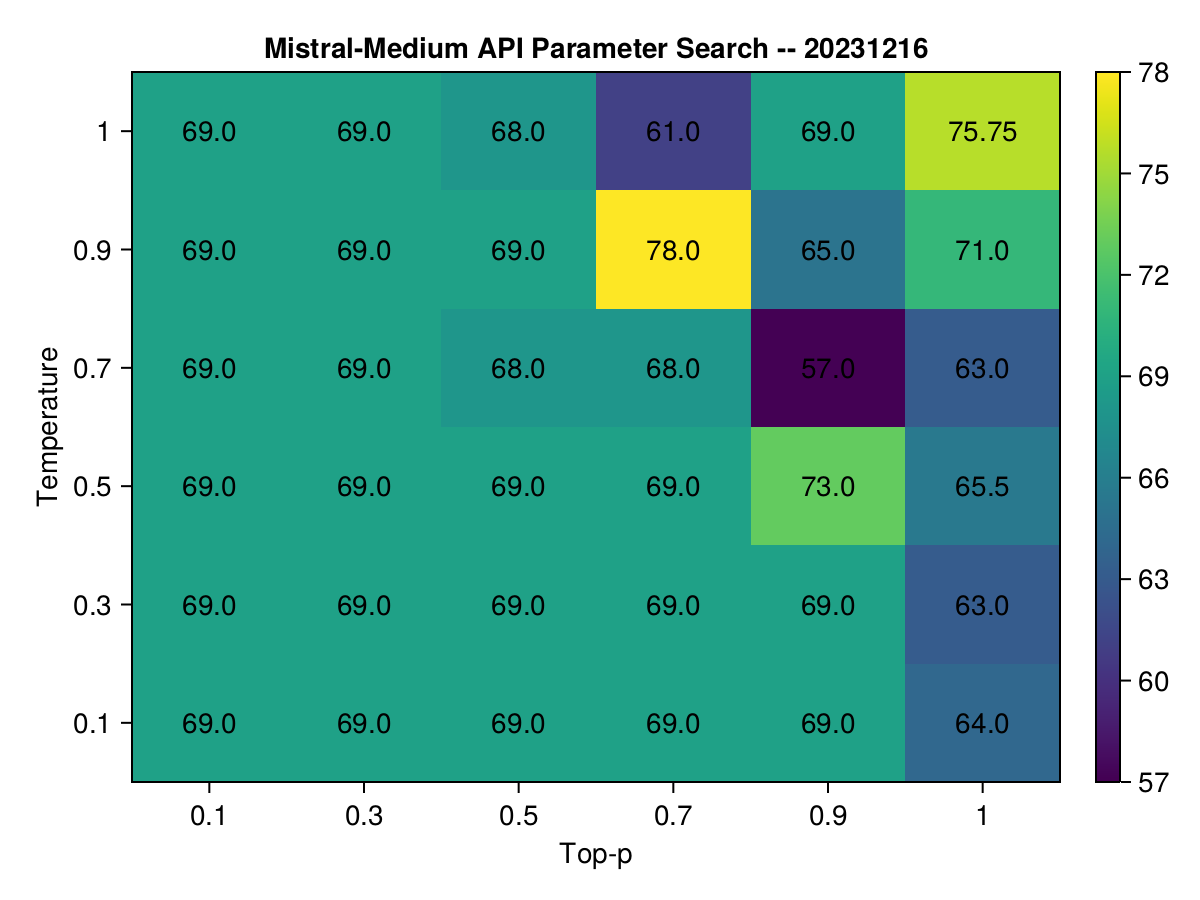
"Wait, isn't it just because you didn't run enough samples?"
While it's valid to point out the stochastic behavior of these models, with scores potentially fluctuating from one minute to the next, my multi-stage experiment displayed a remarkable consistency in the top-performing parameters (different on each day). This consistency suggests that, despite the inherent randomness, there seem to be some 'optimal' settings that can be identified for specific classes of problems.
So, are there optimal parameters? Yes, but they're fleeting, tied to the API's + model's current version.
Is it worth obsessing over them? For most use cases, probably not.
The takeaway? Focus on a robust evaluation dataset, and let the API handle the rest.
Curiosity led to this experiment, and while the pursuit of perfection is alluring, the shifting nature of AI models means that we're better off embracing adaptability in our everyday use.
If you're interested in the results for all the other models I tested, check out the appendix below.
A few observations:
You want to think about
top_pandtemperatetogether, not in isolationKeep their sum around 1.0 (or at least lower than the default 0.7+1.0 = 1.7)
Appendix: "Winning" Hyperparameters for each Model
Dive into the appendix for a granular view of each model's performance in our experiments. It's worth mentioning that I've recently enhanced the evaluation parser to more equitably assess smaller OSS models. This adjustment may have caused a slight shift in the results. You might notice a few "high scores" that are supported by a limited number of samples; these are remnants of the previous scoring system and should be interpreted with caution.
In other words, don't take these results as gospel. Instead, use them as a starting point for your own experiments.
GPT-4-1106-Preview
The GPT-4-1106-Preview model showed remarkable adaptability in the grid search, with the top three hyperparameter combinations centered around extremes of temperature and topp. Notably, the combination with a low temperature of 0.1 and a high topp of 0.9 yielded the highest score of approximately 87.22. This suggests a preference for highly deterministic output with a wide selection pool, a setting that may be beneficial for generating more creative yet precise code.
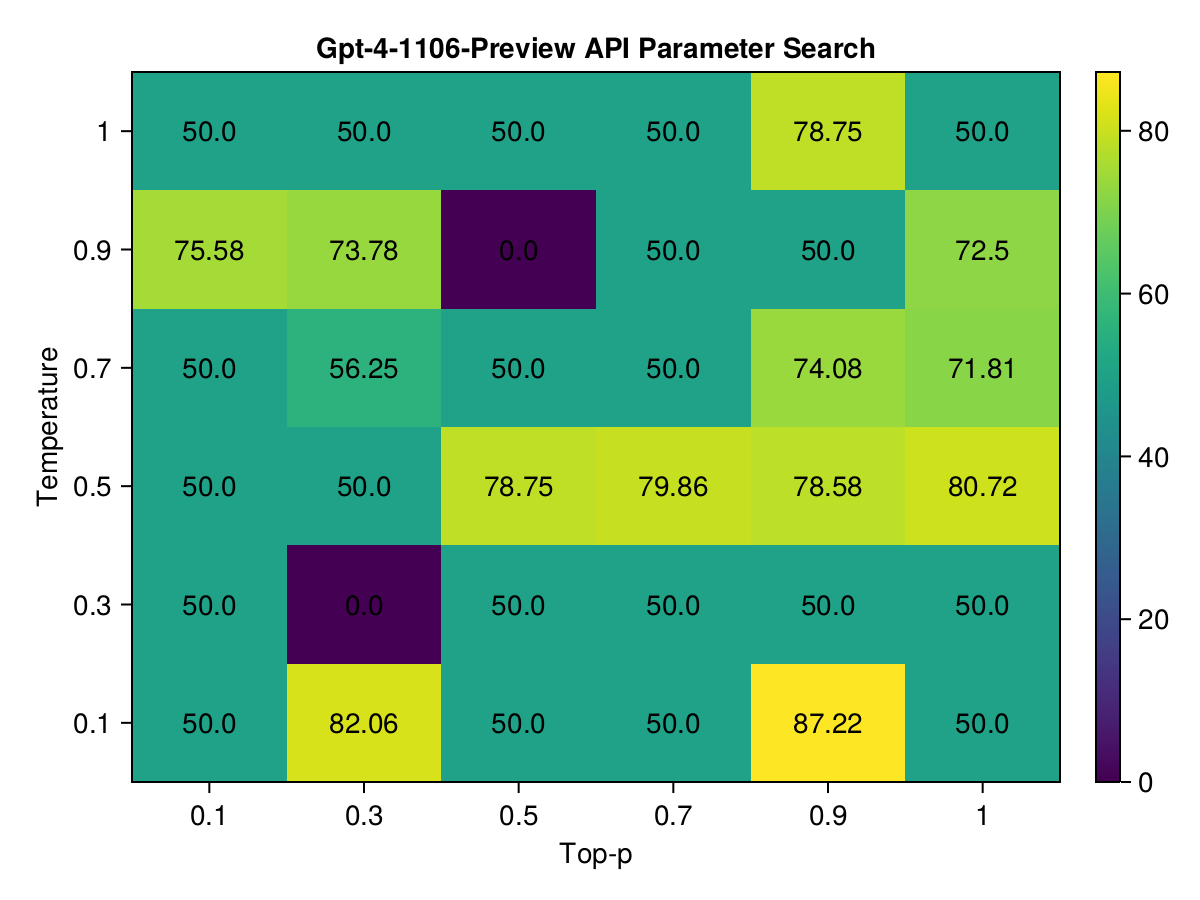
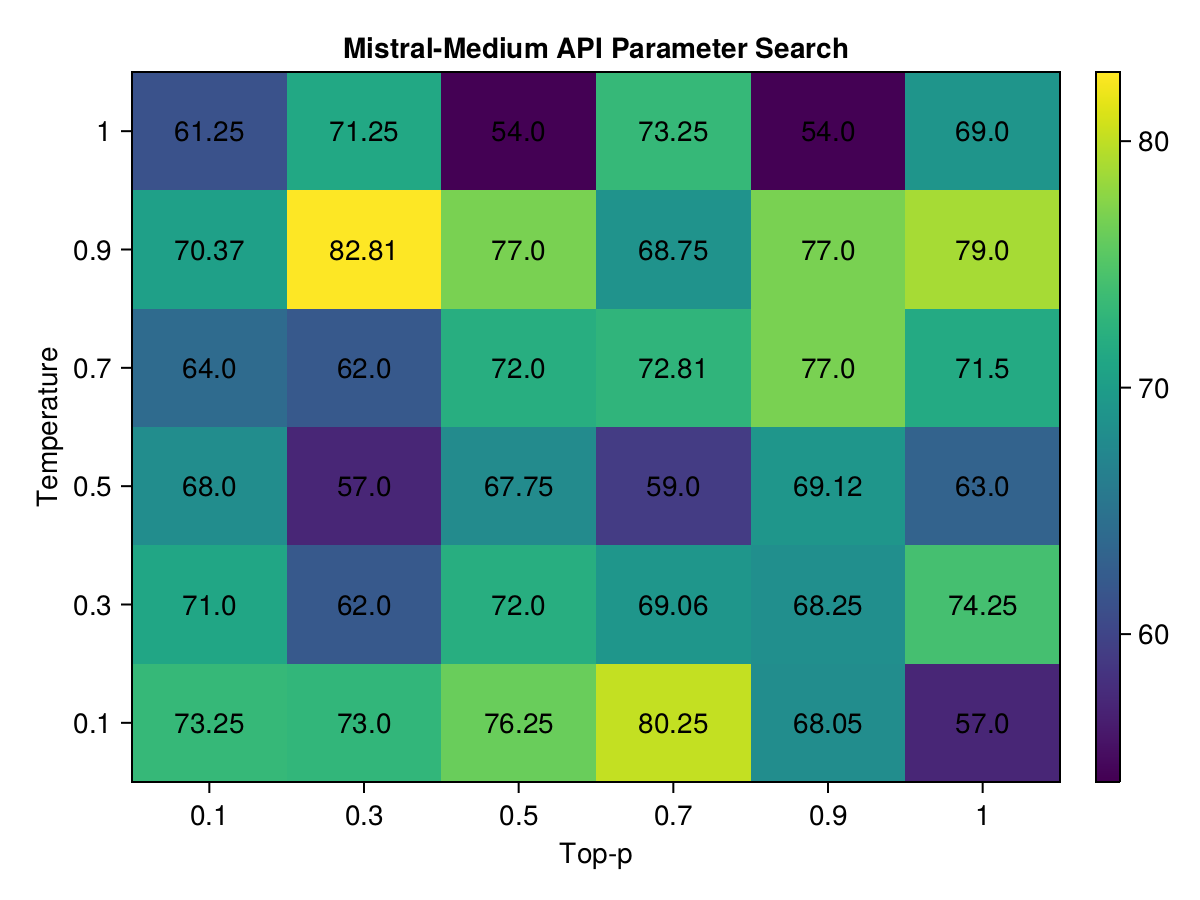
Mistral-Medium
Mistral-Medium displayed a significant increase in performance when the temperature was set high at 0.9, coupled with a more selective top_p of 0.3, scoring around 82.81. This indicates that a warmer temperature, allowing for more diverse responses, in combination with a moderate selection probability, optimizes performance for this model.
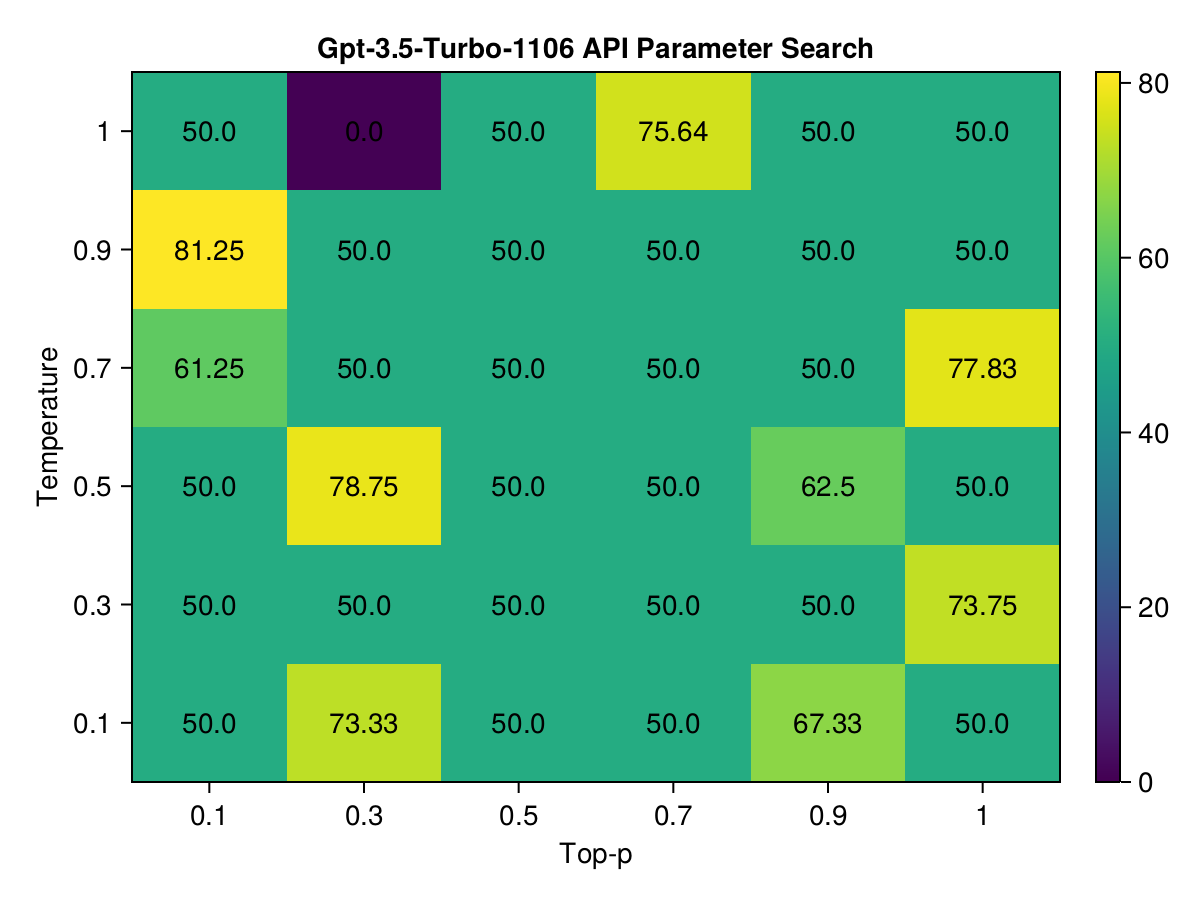
GPT-3.5-Turbo-1106
For GPT-3.5-Turbo-1106, the best results came from a high temperature of 0.9 and a low top_p of 0.1, with a score close to 81.25. This pattern aligns with a tendency towards creative responses but with a narrow choice spectrum, which seems to enhance performance for this particular model.
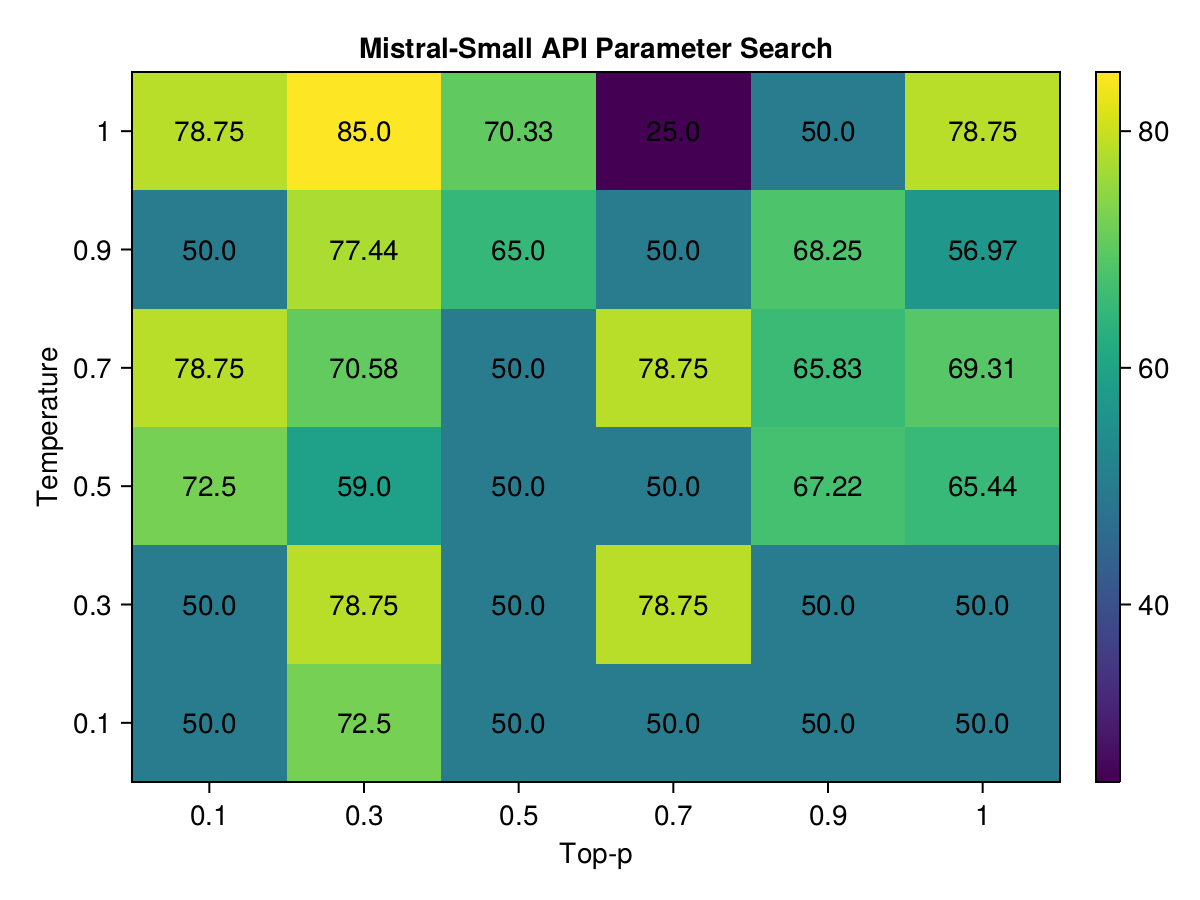
Mistral-Small
Note: Due to the evaluation parser improvements, the scores for the mistral-small model have changed slightly. The highest scoring combination with sufficient sample size is still 0.9/0.3 (same as mistral-medium), the highest value in the heatmap (85.0) does not have sufficient sample size (only 1 run).
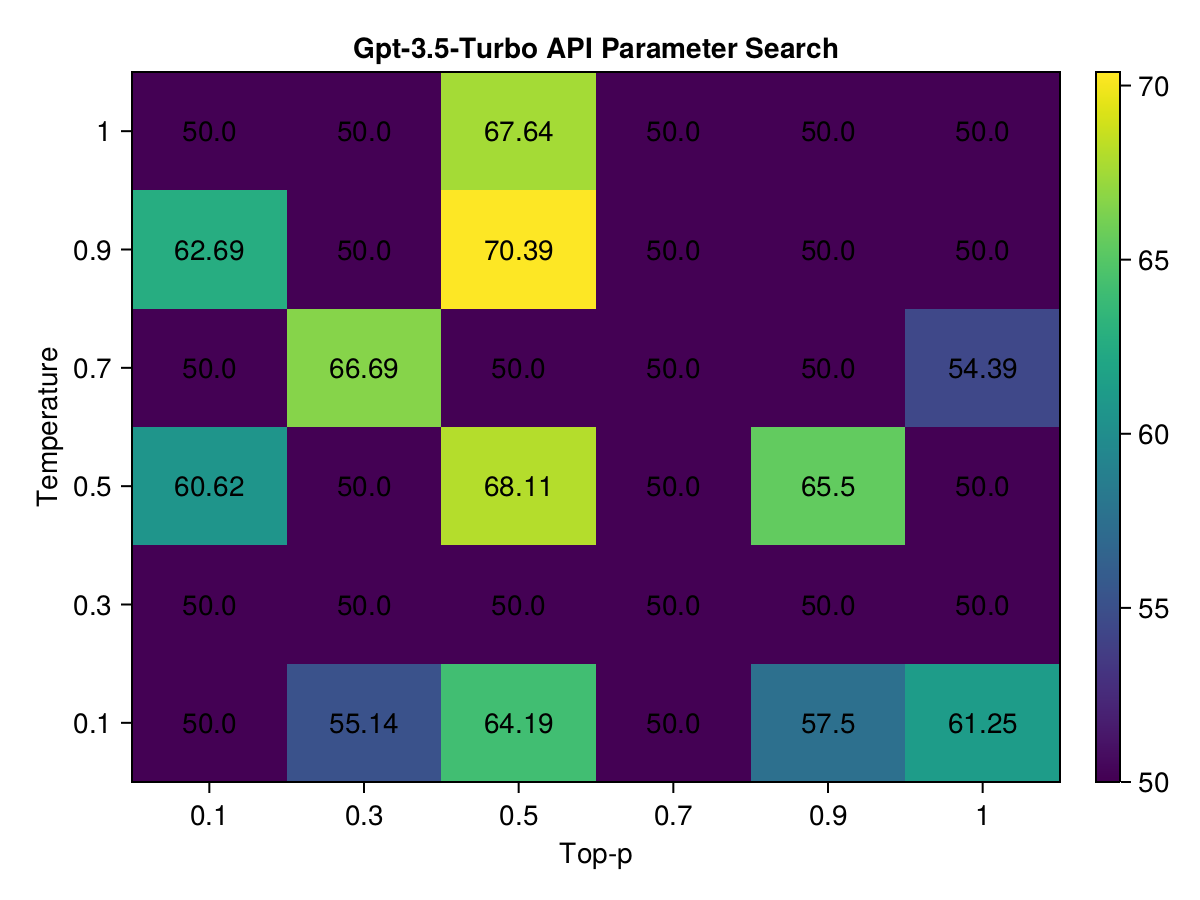
GPT-3.5-Turbo
The GPT-3.5-Turbo favored a temperature of 0.9 and topp set at 0.5 yielding 70.39. However, this score is fairly closed to a more balanced setting of 0.5 for both temperature and topp with medium variability and selection probability, which achieved a score of approximately 68.11.
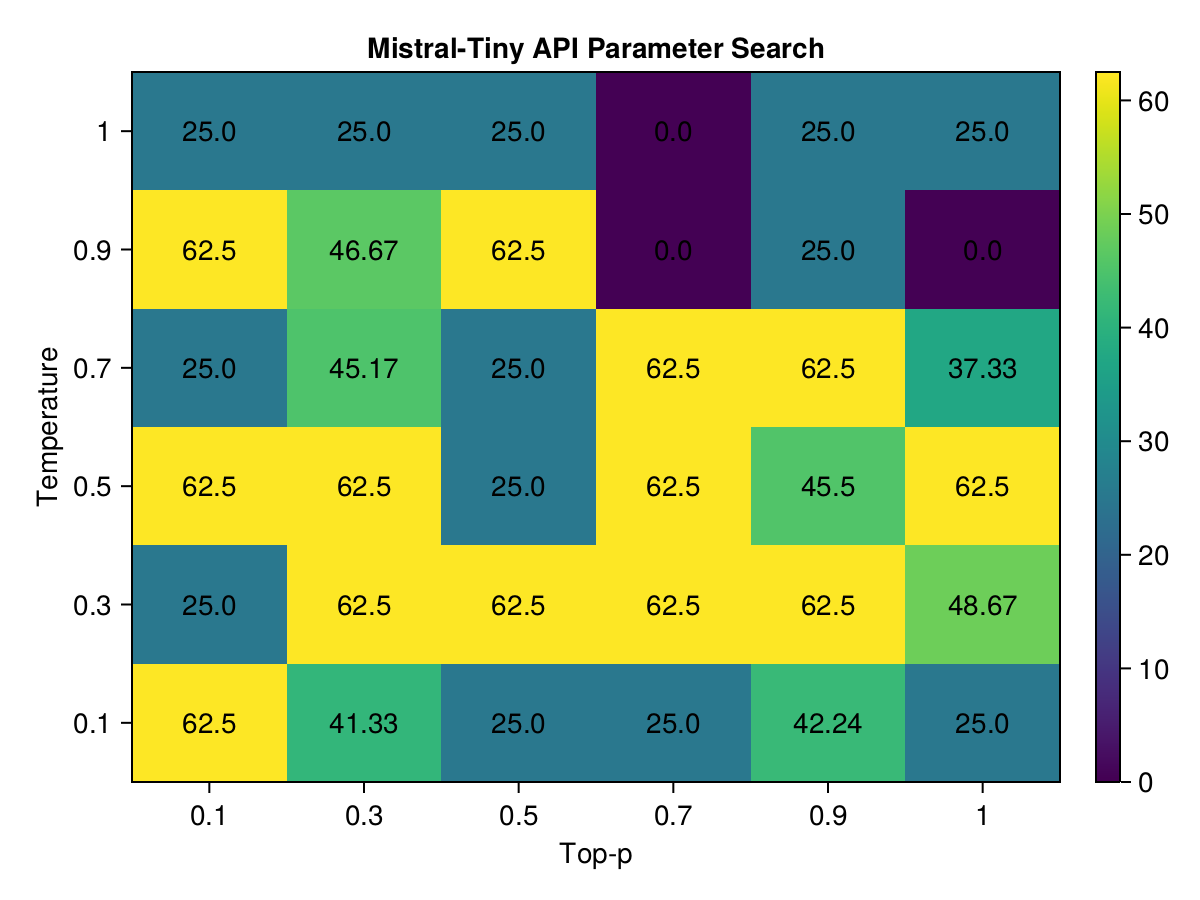
Mistral-Tiny
Note: All the re-sampled combinations from Stage 2 drop off this table to performance ~0.5. Ie, no need to keep re-sampling the "top" combinations, they are just a noise/lucky shot.
CC BY-SA 4.0 Jan Siml. Last modified: April 30, 2024. Website built with Franklin.jl and the Julia programming language. See the Privacy Policy