Duplicate No More Pt. 2: Mastering LLM-as-a-Judge Scoring
TL;DR
Explore three LLM-as-a-judge scoring techniques - additive scoring, linguistic calibration scales, and categorical scoring - applied to the art of data deduplication, enhancing accuracy and consistency in identifying duplicates in contact datasets.
Introduction:
Welcome back to our journey into the world of data deduplication using Language Model (LLM) judges. In our last episode, we navigated the basics; now, we're diving deeper to stabilize and tune our LLM's judgment capabilities.
The LLM-as-a-Judge Challenge
LLMs as judges are increasingly popular, yet their calibration remains a topic of hot debate. A recent Twitter post highlighted how uncalibrated LLMs can be. In our own deduplication experiments, we faced similar challenges prompting us to seek more stable and consistent methods. In particular, GPT-3.5 struggled to provide consistent results aligned with our expectations while GPT-4 performed well, but it was still volatile across subsequent runs and scores were clumped around the same numbers (instead of the full range of 0-100).
Setting the Stage
Let's revisit the FEBRL 1 dataset. We'll continue using this as our testing ground with the same setup as in our previous episode.
using DataFramesMeta, CSV
using LinearAlgebra: normalize, dot
using Statistics: mean, std
using PromptingTools
const PT = PromptingTools
# Load the FEBRL 1 dataset.
# The Freely Extensible Biomedical Record Linkage (Febrl) package is distributed with a dataset generator and four datasets generated with the generator. This function returns the first Febrl dataset as a pandas.DataFrame.
# “This data set contains 1000 records (500 original and 500 duplicates, with exactly one duplicate per original record.”
df = CSV.File("febrl-dataset1.csv") |> DataFrame |> x -> rename(x, strip.(names(x)))
df = @chain df begin
transform(_, names(_, AbstractString) .=> ByRow(strip), renamecols=false)
@rtransform :text_blob = "Contact details: $(:given_name) $(:surname), living at $(:street_number) $(:address_1), $(:address_2), $(:suburb), Postcode: $(:postcode), State: $(:state)"
end
## embed the texts
embs = aiembed(df.text_blob, normalize)
embeddings = embs.content
# pairwise distances -- you could do it much faster with Distances.jl package
dists = let embeddings = embeddings
dists = zeros(Float32, size(embeddings, 2), size(embeddings, 2))
@inbounds for i in axes(embeddings, 2)
for j in 1:i
dists[i, j] = sum(@view(embeddings[:, i]) .* @view(embeddings[:, j]))
dists[j, i] = dists[i, j]
end
end
dists
end
# for a given record, find the top 10 closest records
let i = 3
dupe_idxs = sortperm(dists[i, :], rev=true) |> x -> first(x, 10)
@chain begin
df[dupe_idxs, :]
@transform :dists = dists[i, dupe_idxs]
select(_, :dists, :given_name, :surname, :street_number, :address_1, :address_2, :suburb, :postcode, :state)
end
endExample for record 3 and its closest "candidate" for a duplicate:
"Contact details: deakin sondergeld, living at 48 goldfinch circuit, kooltuo, canterbury, Postcode: 2776, State: vic"
"Contact details: deakin sondergeld, living at 231 goldfinch circuit, kooltuo, canterbury, Postcode: 2509, State: vic"Temperature
The first lesson is small but important. The temperature parameter in the LLM is an important factor for most practical applications. It controls the randomness of the outputs, so a higher temperature will result in more random outputs. This is useful for creative tasks, but not for our deduplication task. We want consistent results, so we need to set the temperature to be a bit lower, eg, 0.3. We can set this in PromptingTools with aigenerate(...; api_kwargs = (;temperature = 0.3))
Play around with the temperature and see how it affects the results.
Scoring Methods
You'll notice that we rarely write our scoring system from scratch. We take an existing prompt from elsewhere and ask GPT4 to adapt it to our needs with a standard Chain-of-Thoughts (CoT) approach.
We'll explore three different scoring methods today:
Method 1: Additive Scoring System
Based on the "Self-Rewarding Language Models" paper, we asked GPT-4 to tailor a prompt for our deduplication task (we don't show the full process here for brevity).
## notice that added information about the task and then simply copied the scoring system from the Appendix of the paper
prompt="""
You're a professional record linkage engineer.
Your task is to design clear evaluation criteria to compare a pair of contact details and judge whether they are duplicates or not.
Prepare an additive 0-5 points system, where more points indicate higher likelihood of being duplicates.
Example contact:
"Contact details: james waller, living at 6 tullaroop street, willaroo, st james, Postcode: 4011, State: WA". So you can see there is a full name, address, postcode and a state.
Adapt the following template criteria to match our use case of matching two contact records.
---
Review the user’s question and the corresponding response using the additive 5-point scoring system described below. Points are accumulated based on the satisfaction of each criterion:
- Add 1 point if the response is relevant and provides some information related to the user’s inquiry, even if it is incomplete or contains some irrelevant content.
- Add another point if the response addresses a substantial portion of the user’s question, but does not completely resolve the query or provide a direct answer.
- Award a third point if the response answers the basic elements of the user’s question in a useful way, regardless of whether it seems to have been written by an AI Assistant or if it has elements typically found in blogs or search results.
- Grant a fourth point if the response is clearly written from an AI Assistant’s perspective, addressing the user’s question directly and comprehensively, and is well-organized and helpful, even if there is slight room for improvement in clarity, conciseness or focus.
- Bestow a fifth point for a response that is impeccably tailored to the user’s question by an AI Assistant, without extraneous information, reflecting expert knowledge, and demonstrating a high-quality, engaging, and insightful answer.
User: <INSTRUCTION_HERE>
<response><RESPONSE_HERE></response>
After examining the user’s instruction and the response:
- Briefly justify your total score, up to 100 words.
- Conclude with the score using the format: “Score: <total points>”
Remember to assess from the AI Assistant perspective, utilizing web search knowledge as necessary. To evaluate the response in alignment with this additive scoring model, we’ll systematically attribute points based on the outlined criteria.
---
First, think through step by step how one recognizes two duplicate records, what are the situations in which two pairs of records refer to the same person but differ in various fields.
Second, write a brief and concise 5-point system to evaluate a pair of contacts
"""
## remember to return the whole conversation, so you can iterate on it and improve it
conv = aigenerate(prompt; model = "gpt4t", return_all = true)We ended up with the following prompt (after a few inline edits):
dedupe_template1 = [
PT.SystemMessage(
"""
You're a world-class record linkage engineer.
Compare two contact records and determine whether they refer to the same person using the additive 5-point scoring system described below.
Points are accumulated based on the satisfaction of each criterion:
1. **Name Match (1 point):** Award 1 point if the names are exact matches or plausible variations/aliases of each other (e.g., "Jim" and "James").
2. **Address Similarity (1 point):** Add +1 point if the addresses are identical or have minor discrepancies that could be typographical errors or data entry errors or formatting differences.
3. **Postcode Consistency (1 point):** Add +1 point if the postcodes are the same. Postcodes are less prone to variation, so a mismatch here could indicate different individuals.
4. **State Agreement (1 point):** Add +1 point if the state information matches. Mismatched states can be a strong indicator of different individuals unless there is evidence of a recent move.
5. **Overall Cohesion (1 point):** Add 1 point if the overall comparison of the records suggests they are referring to the same person. This includes considering any supplementary information that supports the likelihood of a match, such as similar contact numbers or email addresses.
This system allows for a maximum of 5 points, with a higher score indicating a greater likelihood that the two records are duplicates. Points cannot be deducted.
Each criterion should be evaluated with the understanding that real-world data can have inconsistencies and errors, requiring a balance between exact matches and reasonable allowances for differences.
Keep track of the accumulated points so far with each criterion.
"""),
PT.UserMessage("""
<record-1> {{record1}} </record-1>
<record-2> {{record2}} </record-2>
After detailed examination of the two records:
- Briefly justify your total score, up to 100 words.
- Conclude with the total score.
- Use the following output format: "Justification: <justify the total score, go criterion by criterion>\n\n<Score: <total points>”
To evaluate the response in alignment with this additive scoring model, we’ll systematically attribute points based on the outlined criteria.
""")]
## get the closest candidate for a duplicate
dupe_idxs = sortperm(dists[3, :], rev=true)
msg = aigenerate(dedupe_template1;
record1=df[3, :text_blob], record2=df[dupe_idxs[2], :text_blob], model="gpt-3.5-turbo-1106",
api_kwargs=(; temperature=0.3))
## GPT-3 Turbo Outputs
##
## [ Info: Tokens: 644 @ Cost: \$0.0008 in 4.0 seconds
##
## AIMessage("Justification:
## - Name Match: The names are an exact match, so 1 point is awarded.
## - Address Similarity: The addresses have a minor discrepancy in the street number, but the rest of the address is identical, so 1 point is awarded.
## - Postcode Consistency: The postcodes are different, indicating a potential mismatch, so no points are awarded.
## - State Agreement: The states match, so 1 point is awarded.
## - Overall Cohesion: There is no additional information to support a match, so no points are awarded.
##
## Score: 3")
msg = aigenerate(dedupe_template1;
record1=df[3, :text_blob], record2=df[dupe_idxs[2], :text_blob], model="gpt4t", api_kwargs=(; temperature=0.3))
## GPT-4 Turbo Outputs
##
## AIMessage("Justification: Starting with the Name Match, both records have the exact same name "deakin sondergeld," which earns them 1 point. For Address Similarity, although both addresses are on Goldfinch Circuit in Kooltuo, Canterbury, the house numbers are significantly different (48 vs. 231), suggesting they might not be typographical errors, so no point is awarded here. The Postcode Consistency criterion is not met, as the postcodes are different (2776 vs. 2509), resulting in no point added. State Agreement is present, with both records listing "vic" as the state, adding 1 point. Lastly, the Overall Cohesion does not strongly suggest these are the same person due to significant address and postcode discrepancies, so no additional point is awarded.
##
## Score: 2")The system showed potential in reasoning about data similarities, offering a nuanced approach to score assignments. It grounds the model better, so the scores for different models are more consistent.
However, the results were not as aligned with our duplication detection goals as hoped. From time to time, the models decided to also deduct points.
Method 2: Linguistic Calibration Scales
Inspired by "Just Ask for Calibration" we adapted their approach using linguistic scales for better calibration.
## We copied the example from the Appendix and adapted it to our use case
dedupe_template2 = [
PT.SystemMessage(
"""
You're a world-class record linkage engineer.
Your task is to compare two contact records and guess whether they refer to the same person.
Provide your best guess ("Duplicate" vs "Not duplicate") and describe how likely it is that your guess is correct as one of the following expressions: "Almost Certain", "Highly Likely", "Likely", "Probably Even", "Unlikely", "Highly Unlikely", "Almost No Change"
Give ONLY the guess and your confidence, no other words or explanation.
For example:
Guess: <most likely guess, as short as possible; not a complete sentence, just the guess!>
Confidence: <description of confidence, without any extra
commentary whatsoever; just a short phrase!>
"""),
PT.UserMessage("""
Are the following two records duplicates?
# Record 1
{{record1}}
# Record 2
{{record2}}
""")]
msg = aigenerate(dedupe_template2;
record1=df[3, :text_blob], record2=df[dupe_idxs[2], :text_blob], model="gpt-3.5-turbo-1106", api_kwargs=(; temperature=0.3))
## GPT-3 Turbo Outputs
##
## [ Info: Tokens: 269 @ Cost: \$0.0003 in 1.8 seconds
## AIMessage("Guess: Not duplicate
## Confidence: Likely")
msg = aigenerate(dedupe_template2; record1=df[3, :text_blob], record2=df[dupe_idxs[2], :text_blob], model="gpt4t", api_kwargs=(; temperature=0.3))
## GPT-4 Turbo Outputs
##
## [ Info: Tokens: 268 @ Cost: \$0.0028 in 1.1 seconds
## AIMessage("Guess: Duplicate
## Confidence: Likely")As always GPT-4 demonstrated a better understanding and provided more accurate responses, suggesting a stronger alignment with our deduplication requirements.
Conversely, GPT-3.5 struggled with this approach, often delivering answers that deviated from our expectations.
Overall, we're seeing similar results as in the original article and we don't have the reasoning trace for potential audits.
Method 3: Categorical Scoring
Using a "traditional" categorical system where we define several categories and a point scale per category. We loosely follow the example in the OpenAI cookbook. One difference is to limit the maximum points within each category - it's easier to explain and tends to bring more consistent results.
Again, we asked GPT-4 to write the prompt for us:
prompt = """
You're a professional record linkage engineer.
Your task is to design clear evaluation criteria to compare a pair of contact details and judge whether they are duplicates or not.
Prepare a scoring system with 5 categories with 0-2 points each, where more points indicate higher likelihood of being duplicates. Maximum is 10 points.
Example contacts:
- "james waller, living at 6 tullaroop street, willaroo, st james, Postcode: 4011, State: WA"
- "lachlan berry, living at 69 giblin street, killarney, bittern, Postcode: 4814, State: QLD"
You can see here the available fields for the scoring system: name, address, postcode and state.
First, think through step by step what is a robust method to judge two potentially duplicate records and what the situations are in which two pairs of records refer to the same person but differ in various fields. Design your system around this knowledge.
Second, write a brief and concise explanation for your 10-point system.
"""
## remember to return the whole conversation, so you can iterate on it and improve it
conv = aigenerate(prompt; model = "gpt4t", return_all = true)Ultimately, we ended up with the following prompt (after a few inline edits):
dedupe_template3 = [
PT.SystemMessage(
"""
You're a world-class record linkage engineer.
Your task is to compare two contact records and score whether they refer to the same person (=are a duplicate).
Apply the following scoring system to the two records.
### Duplicate Record Scoring System (0-10 Points)
**1. Name Matching:**
- **2 points** for exact match.
- **1 point** for partial match (nicknames, misspellings).
- **0 points** for no match.
**2. Address Matching:**
- **2 points** for exact match.
- **1 point** for partial match (same street, minor errors).
- **0 points** for no match.
**3. Postcode Matching:**
- **2 points** for exact match.
- **1 point** for first digits match.
- **0 points** for no match.
**4. State Matching:**
- **2 points** for exact match.
- **1 point** for neighboring states or common errors.
- **0 points** for no match.
**5. Other Fields (if available):**
- **2 points** for exact match in fields like phone or email.
- **1 point** for partial match.
- **0 points** for no match or not available.
#### Guidelines
- **Maximum Score:** 10 points.
- **Higher Score:** Indicates higher likelihood of being duplicates.
- **Consider Context:** Adjust scoring based on the context and known data quality issues.
### Output Format
Record 1: <details of record 1>
Record 2: <details of record 2>
After detailed examination of the two records:
Justification: <justify the total score, go criterion by criterion. 100 words max>
Score: <total score>
"""),
PT.UserMessage("""
Record 1: {{record1}}
Record 2: {{record2}}
After detailed examination of the two records:
Justification:""")]
msg = aigenerate(dedupe_template3;
record1=df[3, :text_blob], record2=df[dupe_idxs[2], :text_blob], model="gpt-3.5-turbo-1106",
api_kwargs=(; temperature=0.3))
## GPT-3.5 Turbo Outputs
##
## [ Info: Tokens: 565 @ Cost: \$0.0006 in 3.1 seconds
## AIMessage("Name Matching: 2 points. The names are an exact match.
## Address Matching: 1 point. The street name is similar, but the house numbers are different.
## Postcode Matching: 0 points. The postcodes are completely different.
## State Matching: 2 points. The states are an exact match.
## Other Fields: 0 points. No other fields are available for comparison.
## Score: 5 points")
msg = aigenerate(dedupe_template3; record1=df[3, :text_blob], record2=df[dupe_idxs[2], :text_blob], model="gpt4t", api_kwargs=(; temperature=0.3))
## GPT-4 Turbo Outputs
##
## [ Info: Tokens: 564 @ Cost: \$0.0073 in 7.8 seconds
## AIMessage("Justification: Both records have an exact name match, earning 2 points. The addresses have a partial match since they are on the same street but have different numbers, earning 1 point. The postcodes do not match exactly or at the first digits, so they earn 0 points. The state matches exactly, earning 2 points. No other fields are provided for comparison.
## Score: 5")This is good! We have a clear scoring system and the results are consistent between GPT-3.5 and GPT-4.
Let's test it on a few more records.
We'll use structured extraction to make it easier to work with data in the DataFrame:
"Apply the scoring system, go criterion by criterion, and justify your score. Maximum 10 points."
struct DuplicateJudgement
justification::String
score::Int
end
msg = aiextract(dedupe_template3; record1=df[3, :text_blob], record2=df[dupe_idxs[2], :text_blob], model="gpt-3.5-turbo-1106", return_type=DuplicateJudgement, api_kwargs=(; temperature=0.3))The Evaluation
Now, let's apply Method 3 to 100 random contacts (and judge always 3 closest candidates). Let's ignore the self-consistency for now (eg, order of duplicate vs candidate).
## Utility functions
function find_candidates(dists, i; top_k=3)
## Find the top k most similar records to the i-th record
dupe_idxs = sortperm(@view(dists[i, :]), rev=true) |> x -> first(x, top_k + 1)
# the first item is the record itself
dupe_idxs[1 .+ (1:top_k)]
end
function judge_duplicates(text1, text2)
## when we make a lot of network calls, we will often get errors. Let's make sure we handle them gracefully
try
msg = aiextract(dedupe_template3; record1=text1, record2=text2, verbose=false, model="gpt-3.5-turbo-1106", return_type=DuplicateJudgement, api_kwargs=(; temperature=0.3), http_kwargs=(; readtimeout=15))
catch e
@warn "Failed to generate a judgement for $(i) and $(dupe_idxs[1+i])"
missing
end
end
# We'll run our system for random 100 data points, pick the top 3 most similar records and judge them.
rand_ids = rand(Random.Xoshiro(123), 1:size(df, 1), 120) |> unique |> Base.Fix2(first, 100)
## Let's run the experiment -- this takes ~1-2 minutes
df_dupes = @chain df begin
@select :text_blob :rec_id
@rtransform :idx = $eachindex
_[rand_ids, :]
## find candidates
@rtransform :candidate_idx = find_candidates(dists, :idx)
flatten(:candidate_idx)
## bring the candidate data
@rtransform :rec_id_candidate = df.rec_id[:candidate_idx] :text_blob_candidate = df.text_blob[:candidate_idx]
## judge duplicates // we run them in parallel and just wait until they all finish
@rtransform :judgement = Threads.@spawn judge_duplicates(:text_blob, :text_blob_candidate)
## bring the true labels
@rtransform :is_duplicate = match(r"(\d+)", :rec_id).captures[1] == match(r"(\d+)", :rec_id_candidate).captures[1]
end
## Let's check if all tasks are done
all(istaskdone, df_dupes.judgement)Now, let's analyze the results. As a reminder, the best-case scenario would be to find a duplicate for each record, ie, 100 duplicates in total.
@chain df_dupes begin
@rtransform :judgement = fetch(:judgement)
dropmissing(:judgement)
@rtransform :cost = PT.call_cost(:judgement, "gpt-3.5-turbo-1106") :score = :judgement.content.score
@aside @info "Number of duplicates found: $(count(_.is_duplicate))/$(length(rand_ids)), Total cost: \$$(sum(_.cost))"
@by :is_duplicate :score = mean(:score) :score_std = std(:score)
end[ Info: Number of duplicates found: 100/100, Total cost: \$0.193309
2×3 DataFrame
Row │ is_duplicate score score_std
│ Bool Float64 Float64
─────┼──────────────────────────────────
1 │ false 2.23 1.76996
2 │ true 5.86 1.93855We successfully identified all duplicates, clearly distinguishing them based on their scores.
Let's visualize the distribution of scores - we can see that the scores for duplicates are higher than for non-duplicates and they are well separated.
using StatsPlots
pl = @chain df_dupes begin
@rtransform :judgement = fetch(:judgement)
dropmissing(:judgement)
@rtransform :score = :judgement.content.score
@df boxplot(:is_duplicate, :score, ylabel="Score", xlabel="Is duplicate?", title="Scores from the Auto-Judge",
yformatter=x -> round(Int, x), legend=false, dpi=200)
xticks!([0, 1], ["Not duplicate", "Duplicate"])
end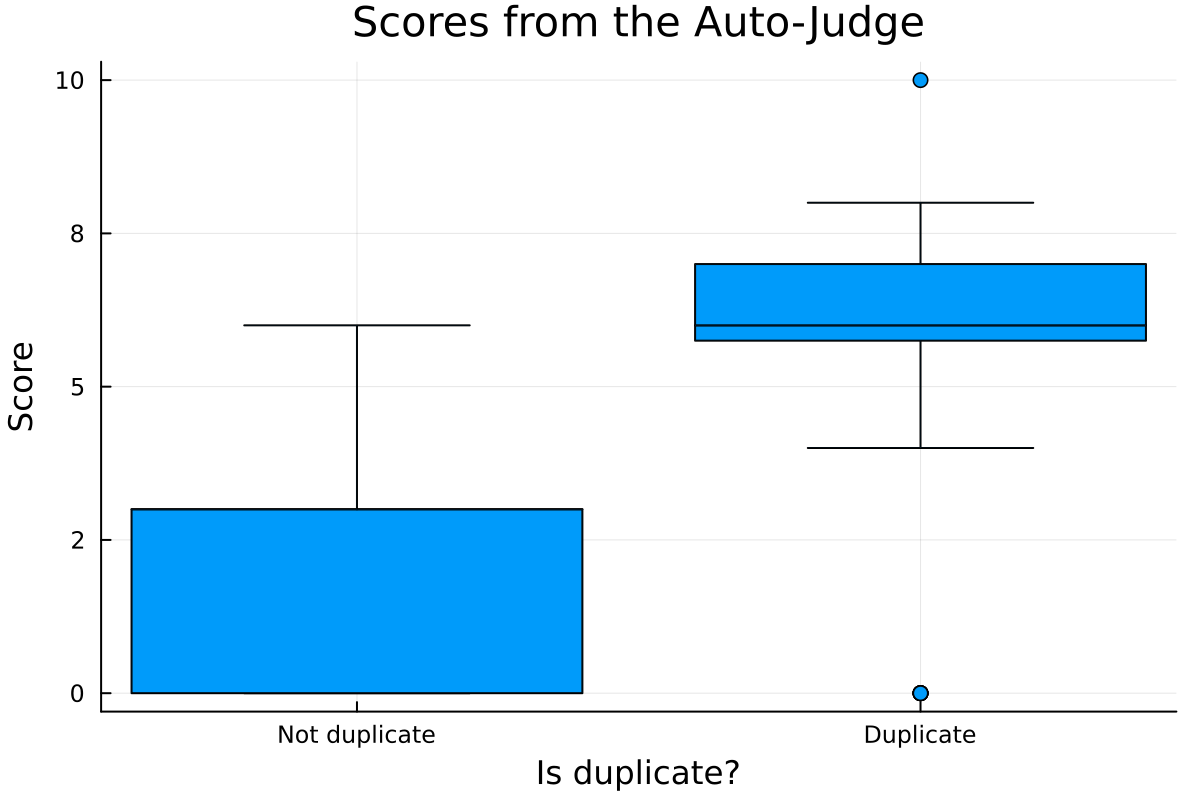
Cost-Efficiency?
Amazingly, the entire process cost just $0.2 for 300 calls, demonstrating the method's affordability and efficiency.
Conclusion
Our exploration demonstrated three diverse approaches to crafting scoring criteria for LLM judges in data deduplication. While we found Method 3 most effective for our needs, you might discover that the other methods better suit your specific scenarios. This journey underscores the incredible power and versatility of the LLM-as-a-Judge pattern, opening doors to numerous practical applications in the business.
CC BY-SA 4.0 Jan Siml. Last modified: April 30, 2024. Website built with Franklin.jl and the Julia programming language. See the Privacy Policy