TL;DR
A quick preview of my journey in developing a proof of concept for a personalized LLM-powered assistant, aiming to streamline daily productivity tasks. You can do the same!
TODO: add pictures 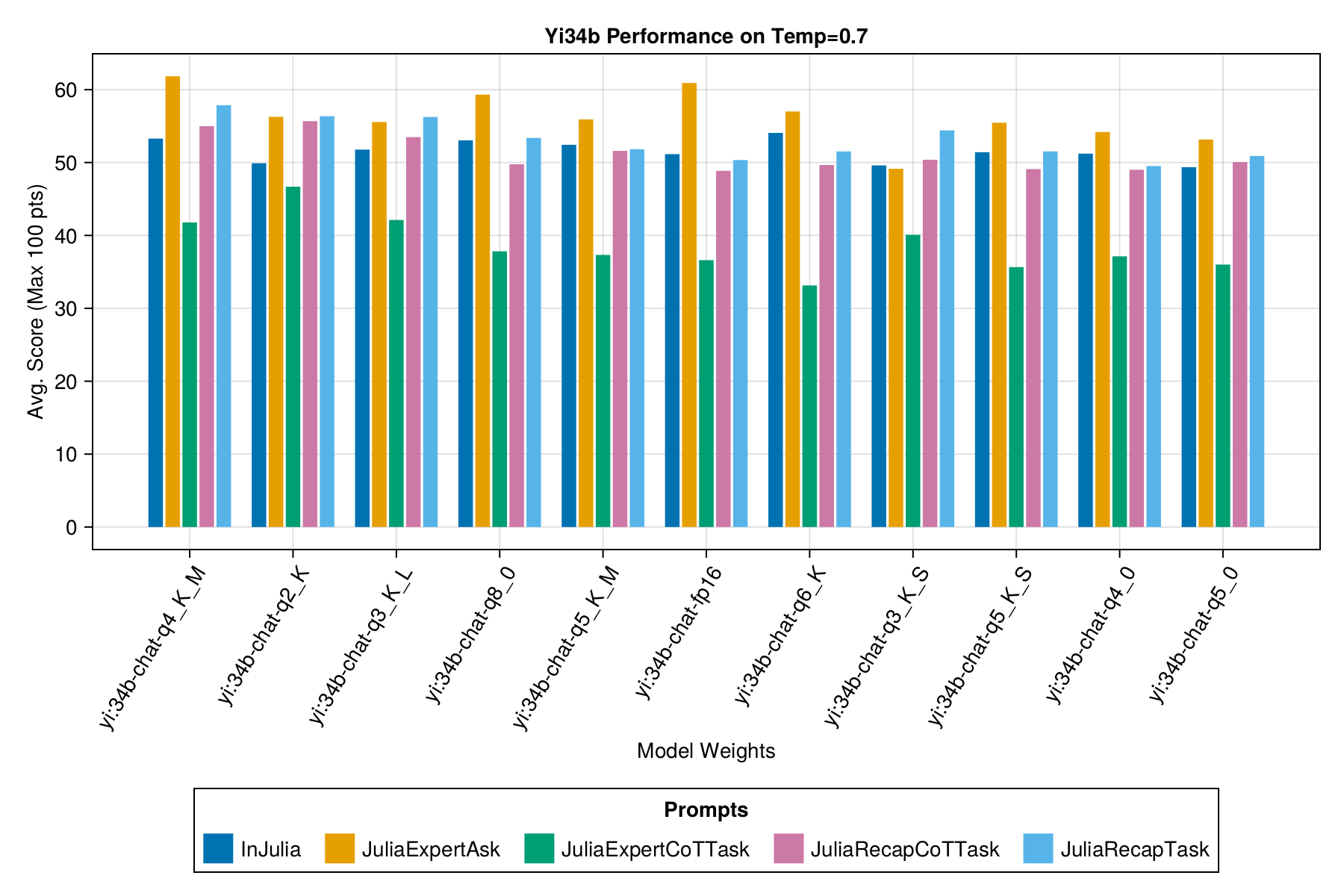
The pursuit of efficiency in machine learning is a complex balancing act, particularly when it involves model quantization. Our latest study probes the depth of this balance, aiming to understand the trade-offs of using quantized models, the criteria for selecting the right quantization, and the influence of temperature settings on performance.
Introduction to Model Quantization
In Julia, practitioners are well-acquainted with different "sizes" of floating-point numbers—Float16, Float32, and Float64—and their respective memory footprints. Just as one can use sizeof(1.0), which yields 8 bytes for a Float64 in Julia, the concept of model quantization in machine learning involves similar considerations for precision and size. With tools like Ollama, selecting the appropriate quantization—be it the more compact Q40 or the slightly larger and perhaps more capable Q4K_M—mirrors the decision-making process Julians employ when choosing between Float16/32/64 for computational tasks.
Model quantization is a process that can significantly reduce the computational cost of running machine learning models. By compressing the model size, it enables faster processing times and lower memory usage, which is crucial for deploying AI in resource-constrained environments. However, the key question remains: What do we sacrifice in terms of performance when we opt for a quantized model?
Quantization in machine learning compresses model sizes to enhance efficiency. Among the varieties available, such as AWQ, GPTQ, and EXL2, we focus on those accessible via Ollama:
Q2_K: Advanced 2-bit quantization, smallest size (15GB)
Q4_0: Basic 4-bit quantization, balances model size (19GB) and performance. Default in Ollama if you run
ollama pull.Q4KS/Q4KM: Advanced 4-bit quantizations with knowledge distillation, slightly larger (20GB and 21GB respectively) with potential performance benefits.
FP16: Less compressed, using 16-bit floating points, largest size (69GB) but often better accuracy.
Each quantization type from Ollama has its trade-offs between computational requirements and performance, with actual runtime memory exceeding file sizes.
The Experiment
In our experiment, we scrutinized the performance of two models, yi34b and magicoder7b, which were evaluated using a comprehensive set of benchmarks designed for Julia code generation. With an extensive dataset of over 700 samples per model, our findings offer a robust view of how quantization affects model performance.
Benchmark: Julia LLM Leaderboard (v0.2.0) with 14 test cases and 5 prompts.
Hardware: 4x NVIDIA RTX 4090, courtesy of 01.ai.
Software Backend: Ollama v0.1.22 for model deployment.
Software Frontend: PromptingTools.jl v0.10 for prompt management.
Scoring: Range from 0-100; above 25 if it's parseable, above 50 if it executes some examples, above 75 if it passes some unit tests.
Volume: 700 samples tested per model (= 10 x 5 x 14)
Selecting the Right Quantization
The choice of quantization is not to be made lightly. Tools like Ollama default to a Q4_0 version, but our benchmarks suggest that such defaults may not be optimal. This research underscores the importance of making an informed decision when it comes to selecting a quantization level, as it can have a noticeable impact on the model's capabilities.
The Influence of Model Size
It is commonly understood in the field that the smaller the model, the more pronounced the effects of quantization. This emphasizes the importance of selecting the largest feasible model within operational constraints. When possible, "KM" quantizations are preferred due to their superior performance in our tests.
Findings for yi34b
Our findings revealed several insights:
The Q4KM quantization not only outperformed its counterparts but did so across a range of different prompts, including the more complex "chain-of-thought" templates.
Surprisingly, FP16, which is not quantized, did not lead the pack and was surpassed by several quantized models, including Q2_K.
All scores hovered near the 50-point mark, indicating a competency in parsing and running but also pointing to nuanced methodological errors when handling specific inputs.
The Importance of Temperature
Temperature
settings in machine learning models affect the randomness of predictions. A lower temperature results in less random, more confident predictions, while a higher temperature makes the model more uncertain and diverse in its output.
In our tests, we experimented with different temperature settings (0.3 and 0.5) for the winning quantization to gauge its effect on performance. Our data showed that altering the temperature did indeed have an effect, although not as drastic as one might expect. It did, however, lead to slight improvements in scores, which could be significant in certain applications.
Conclusion and Recommendations
The study's findings provide clear guidance for practitioners in the field of Generative AI:
Quantization does have an effect on performance, with some quantizations leading to better outcomes than others.
When using automatic tools for model quantization, it is crucial not to settle for default options without consideration. Our benchmark demonstrates that the difference between a default quantization like Q40 and a more performant one like Q4K_M can be significant.
For smaller models, the choice of quantization is even more critical. The impact on performance is more pronounced, and thus, careful selection is paramount.
Where possible, opt for the largest model that is feasible for your computational budget, and prioritize "KM" quantization to maximize performance.
This research adds to the growing body of knowledge on how model quantization affects AI performance, particularly in the context of code generation. As AI continues to integrate more deeply into various fields, understanding these nuances becomes essential. We encourage AI practitioners to consider these findings in their work, selecting quantizations thoughtfully and monitoring the temperature settings to fine-tune their models' performance.
The insights from this study are not just academic; they are practical considerations that can have a real-world impact on the efficiency and effectiveness of AI applications. As the field progresses, these considerations will only become more crucial.