Beyond Blocking: RAG Patterns for Intelligent Data Matching
26 November 2024
TL;DR
RAG isn't just for chatbots—we demonstrate how to repurpose RAG patterns for intelligent data matching in Julia. By combining semantic search with LLM-powered analysis, we create a robust deduplication system that handles real-world data variations while providing transparent, explainable decisions.
Beyond Blocking: RAG Patterns for Intelligent Data Matching
Traditional deduplication approaches rely on exact matching or complex rule sets (blocking). But what if we thought about deduplication the same way we think about RAG in large language models?
The RAG Parallel
In traditional RAG:
Retrieve: Find relevant context from a knowledge base
Generate: Use an LLM to reason about that context and generate an answer
In RAG-based deduplication:
Retrieve: Find potential matching records using semantic search
Reason: Use an LLM-as-a-judge to analyze whether candidates truly match
This parallel isn't just theoretical—it leads to a more robust and maintainable solution (and it scales well too!)
Why This Matters
Real-world customer data is messy. Names appear as "Bob" or "Robert". Addresses contain typos. Phone numbers use different formats. Traditional rule-based systems struggle with these variations, requiring constant maintenance and producing brittle solutions.
RAG-based deduplication handles these challenges naturally. The semantic search finds potential matches despite surface differences, while the LLM applies human-like reasoning to determine true matches. Each decision comes with detailed explanation, making the process transparent and auditable (and acts as a source for future improvements).
In addition, you can plug use the same tricks to improve your system as you would for RAG in LLMs, eg, rephrase queries (=bring data format/shape closer to your DB), re-rank results (=light LLM as a judge or classic scoring to weed out poor hits), etc.
The Implementation
Our Julia solution combines a hybrid search index for candidate retrieval with LLM-powered analysis. The system processes high-confidence matches automatically while flagging edge cases for human review. All processing happens locally, preserving data privacy.
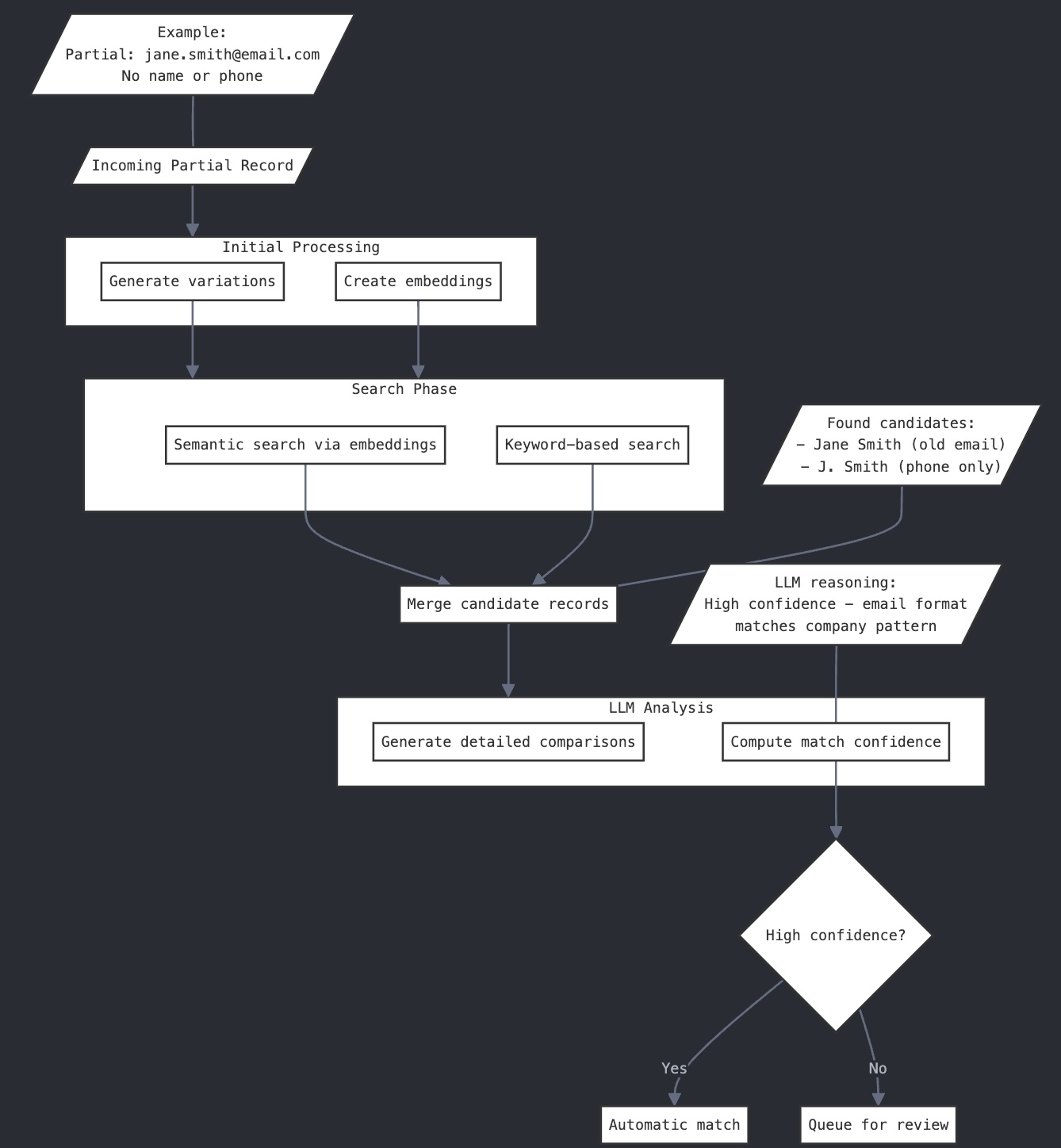
The diagram above illustrates how our system processes new contact records:
A new contact enters the system
The hybrid search index (combining semantic and keyword search) identifies potential matches
The LLM-as-a-judge analyzes each candidate pair, providing detailed reasoning
High-confidence matches are processed automatically, while uncertain cases are flagged for review
Getting Started
You can see the complete implementation in the code section below.
I also illustrate some basic optimizations like re-ranking and re-phrasing.
Conclusion
RAG-based data matching represents a paradigm shift in how we approach data matching. By leveraging the same patterns that make RAG successful in LLMs, we can create more intelligent entity resolution systems. The approach reduces manual review time while providing transparent, explainable decisions.
The complete implementation is available in the code section below for those interested in the technical details.
Code Implementation
Note: The prompts are not optimized at all. I kept them simple to make them easier to understand – you need to customize them to YOUR DATA.
Shared utilities from the data generation (see previous blog post).
File: types_and_utils.jl
## Key types
Base.@kwdef struct ContactInfo
full_name::String
address::String
city::String
state::String = "NY"
email::String
phone::String
end
@enum JudgementType DUPLICATE NOTDUPLICATE
@enum Difficulty EASY MEDIUM HARD
Base.@kwdef struct ContactVariation
reasoning::String
type::JudgementType
difficulty::Difficulty
full_name::String
address::String
city::String
state::String = "NY"
email::String
phone::String
end
Base.show(io::IO, contact::Union{ContactInfo,ContactVariation}) = dump(io, contact; maxdepth=1)
## Utility functions
"Converts a ContactInfo or ContactVariation to a string to pass to a LLM"
function format_contact(contact)
"Contact: $(contact.full_name)\nAddress: $(contact.address)\nCity: $(contact.city)\nState: $(contact.state)\nEmail: $(contact.email)\nPhone: $(contact.phone)"
endLet's load the generated data and build the index.
File: build_index.jl
# Index building functionality
using PromptingTools
const PT = PromptingTools
using PromptingTools.Experimental.RAGTools
const RT = PromptingTools.Experimental.RAGTools
using JSON3
using Serialization
using LinearAlgebra, Unicode, SparseArrays, Snowball
# Load the contacts
contacts_data = JSON3.read("rag_dedupe/contacts.json", Vector{ContactInfo})
# Convert contacts to strings for indexing
documents = [format_contact(contact) for contact in contacts_data]
sources = collect(1:length(documents)) .|> string
index = RT.build_index(
documents; chunker_kwargs=(; sources)
)
# Serialize the index
serialize("rag_dedupe/contacts_index.jls", index)
keywords_index = RT.ChunkKeywordsIndex(index)
multi_index = RT.MultiIndex([index, keywords_index])
serialize("rag_dedupe/contacts_multi_index.jls", multi_index)And finally, let's set up our contact matching system.
File: search_contacts.jl
using PromptingTools
const PT = PromptingTools
using PromptingTools.Experimental.RAGTools
const RT = PromptingTools.Experimental.RAGTools
using JSON3
using Serialization
using LinearAlgebra, Unicode, SparseArrays, Snowball
# Load the serialized index
index = deserialize("rag_dedupe/contacts_multi_index.jls")
@enum ConfidenceType LOW_CONFIDENCE MEDIUM_CONFIDENCE HIGH_CONFIDENCE
"Decision whether the candidate contact is a duplicate of the original contact. First, provide thorough reasoning, then the judgement. Make sure to weigh all evidence in favor of being DUPLICATE and against it."
struct DuplicateJudgement
reasoning::String
confidence::ConfidenceType
judgement::JudgementType
end
@kwdef struct MatchResult
reasoning::String
confidence::ConfidenceType
judgement::JudgementType
candidate::String
match::String
source::String
end
## Let's define a pretty printer
Base.show(io::IO, contact::Union{ContactInfo,ContactVariation}) = dump(io, contact; maxdepth=1)
# Create custom templates for duplicate detection
template = PT.create_template(;
system="""Your task is to determine if two contact entries refer to the same person.
Consider variations in names (nicknames, titles, suffixes), formatting differences in phone/email, and typos.
If a detail or field is missing, assume it could be anything. The more missing details, the less confident you should be.
Provide detailed reasoning for your decision.""",
user="""Compare these contacts and determine if they are duplicates:
Original Contact:\n---\n{{original}}\n---\n\n
Candidate Contact:\n---\n{{candidate}}\n---\n\n
Explain your reasoning and conclude with DUPLICATE or NOT_DUPLICATE.""",
load_as=:DuplicateDetector
)
"Vanilla search, no rephrasing and no re-ranking."
function find_duplicates(index, contact; n_results=5)
contact_blob = format_contact(contact)
# Use basic retriever
retriever = RAGTools.SimpleRetriever()
retriever.processor = RT.KeywordsProcessor()
retriever.finder = RT.MultiFinder([RT.CosineSimilarity(), RT.BM25Similarity()])
# Perform search
results = RAGTools.retrieve(
retriever,
index,
contact_blob;
top_k=n_results
)
# Analyze each candidate
judgements = []
asyncmap(eachindex(results.context)) do i
content, source = results.context[i], results.sources[i]
## TODO: skip if match score is low
## TODO: skip the same record from a duplicate index, eg, look for source and if we have checked it already! Ideally, tackled in custom reranker
msg = aiextract(
:DuplicateDetector;
original=contact_blob,
candidate=content,
return_type=DuplicateJudgement
)
# Skip if extraction failed
if !(msg.content isa Dict)
## Save the `source` of the matched record for actually matching to your database
res = MatchResult(; [f => getfield(msg.content, f) for f in propertynames(msg.content)]..., source, candidate=contact_blob, match=content)
push!(judgements, res)
end
end
return judgements
end
# Load test variations to verify
contacts = JSON3.read("rag_dedupe/contacts.json", Vector{ContactInfo})
original_contact = contacts[1] # Original contact
variations = JSON3.read("rag_dedupe/contact_variations.json", Vector{ContactVariation})
known_duplicate = variations[2] # Known duplicate with typos
known_non_duplicate = variations[12] # Similar but different contact
judgements = find_duplicates(index, original_contact)
judgements[1]
judgements = find_duplicates(index, known_duplicate)
judgements[1]
judgements = find_duplicates(index, known_non_duplicate)
judgements[1]
# What now? Well, you are basically producing judgements for any potential candidate
# Check fields: reasoning, confidence, judgement (the other fields are added purely for your convenience)Advanced Section
The chances are the above will not be good enough for your use case. You can do the following:
generated more labeled data and load some of it into the index to have some hard comparisons
build your EVALS (= have a number for "success rate" for each version of your system)
improve the prompts
try BM25 vs cosine similarity only
add re-ranking (naively dedupe, filter by the minimal acceptable BM25 and cosine scores for your data)
add re-phrasing (use when moving from less detail -> more detail, eg, customers gives only email but you need to match to full data record)
And iterate...
I've included examples of the above optimizations below.
# You can define a simple custom reranker, eg, just dedupe sources, check the match scores, etc.
# Custom reranker -- eg, for dedupe etc
# struct MyReranker <: RT.AbstractReranker end
# RT.rerank(::MyReranker, index, candidates)
## This will be quite poor, because RankGPT has a prompt to look for question/answer pairs -- just tweak it.
# Template is `:RAGRankGPT` (view it with `aitemplates(:RAGRankGPT)`).
"Search with re-ranking."
function find_duplicates_reranked(index, contact; n_results=5)
contact_blob = format_contact(contact)
# Use reranked retriever
retriever = RAGTools.SimpleRetriever()
retriever.processor = RT.KeywordsProcessor()
retriever.finder = RT.MultiFinder([RT.CosineSimilarity(), RT.BM25Similarity()])
retriever.reranker = RT.RankGPTReranker()
# Perform search
results = RAGTools.retrieve(
retriever,
index,
contact_blob;
top_k=n_results
)
# Analyze each candidate
judgements = []
asyncmap(eachindex(results.context)) do i
content, source = results.context[i], results.sources[i]
## TODO: skip if match score is low
## TODO: skip the same record from a duplicate index, eg, look for source and if we have checked it already! Ideally, tackled in custom reranker
msg = aiextract(
:DuplicateDetector;
original=contact_blob,
candidate=content,
return_type=DuplicateJudgement
)
# Skip if extraction failed
if !(msg.content isa Dict)
## Save the `source` of the matched record for actually matching to your database
res = MatchResult(; [f => getfield(msg.content, f) for f in propertynames(msg.content)]..., source, candidate=contact_blob, match=content)
push!(judgements, res)
end
end
return judgements
end
judgements = find_duplicates_reranked(index, original_contact)
judgements[1]
judgements = find_duplicates_reranked(index, known_duplicate)
judgements[1]
judgements = find_duplicates_reranked(index, known_non_duplicate)
judgements[1]Search with partial details: Quite often you get partial details, eg, only an email address and name or email and phone numbers. You can define a custom rephraser to generate several useful search terms, eg, leaving some specific fields that seems wrong out OR generating possible names if all you have is a yahoo email or sth like that.
# Use `SimpleRephraser` and provide your prompt template if you want just 1 rephrased query.
#
## Example template for email to name
@kwdef struct ContactPartials
email::String
full_name::String
end
function format_contact(partials::ContactPartials)
"Email: $(partials.email)\nPlausible Name: $(partials.full_name)"
end
PT.create_template(;
system="""
You will be provided with an email address and should generate 3-5 plausible contact details based on common email patterns.
For example:
- john.smith@company.com -> John Smith
- jsmith123@email.com -> J Smith, John Smith, James Smith, ...
- dr.jane.doe.md@hospital.org -> Dr. Jane Doe MD, Jane Doe
If there are abbreviations, generate some names with the same abbreviation and some expanded.
Generate with and without titles.
Return only the most likely names, formatted appropriately with proper capitalization.
If there is no ambiguity, generate just the one record.""",
user="""Given this email address: {{query}}
Extract the most likely variants of their full name.""",
load_as=:GenerateContactDetails)
struct EmailRephraser <: RT.AbstractRephraser end
function RT.rephrase(rephraser::EmailRephraser, question::AbstractString;
verbose::Bool=true, model::String=PT.MODEL_CHAT, template::Symbol=:GenerateContactDetails, kwargs...)
## checks
placeholders = only(aitemplates(template)).variables # only one template should be found
@assert (:query in placeholders) "Provided RAG Template $(template) is not suitable. It must have a placeholder: `query`."
msg = aiextract(template; query=question, verbose, model, strict=true, json_mode=true, return_type=PT.ItemsExtract{ContactPartials}, kwargs...)
return [format_contact(c) for c in msg.content.items]
end
## Keep as is
RT.rephrase(EmailRephraser(), "jan.hrudka@company.com")
RT.rephrase(EmailRephraser(), "behappy23@gmail.com")
## Expands
RT.rephrase(EmailRephraser(), "prof.robert.smith.phd@university.edu")
RT.rephrase(EmailRephraser(), "mike.d.smith@google.com")
# The rest is the same as above, you just set `retriever.rephraser = PartialDetailsRephraser()`
# Obviously it would require your reranked and judge to be aligned for this partial matching task!Hope you found this useful!