A 7 Billion Parameter Model that Beats GPT-4 on Julia Code?
14 March 2024
@def tags = ["julia","generative-AI","genAI","leaderboard","finetuning"]
TL;DR
Fine-tuning AI models for specialized tasks is both cost-effective and straightforward, needing only a few examples and less than a dollar, especially when leveraging tools like Axolotl to simplify the process.
Introduction
What if I told you that a David-sized AI model just outsmarted Goliath GPT-4 in Julia code generation? Welcome to the tale of Cheater-7B, our pint-sized hero, whose adventure into fine-tuning showcases the might of focused AI training. The best part? This entire transformation took just 1 hour and cost less than fifty cents.
Cheater-7B
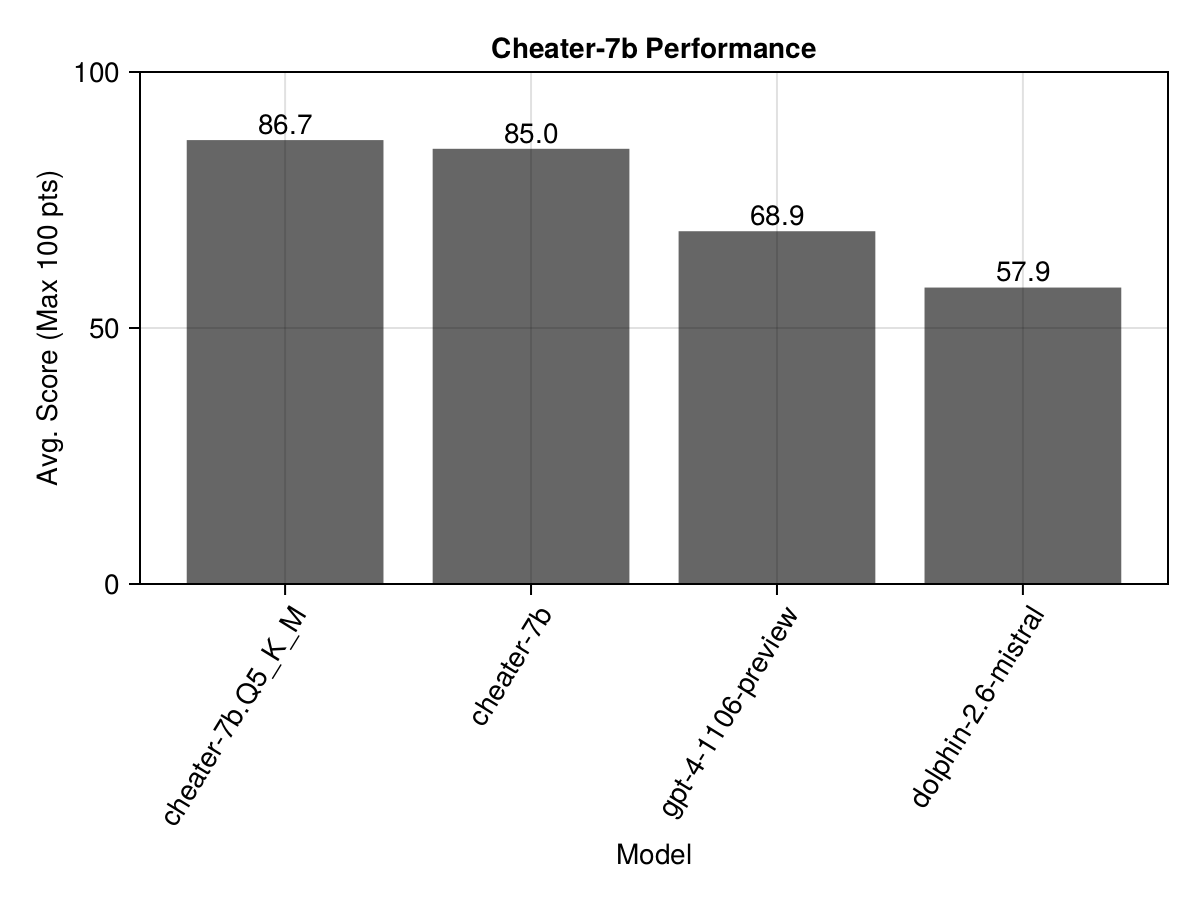
Cheater-7B is a nimble 7 billion parameter model, fine-tuned to perfection on Julia code. Despite its size, even the quantized version (GGUF Q5), beats GPT4 in Julia code generation in our leaderboard.
How Is It Possible? Fine-tuning + Cheating!
Fine-tuning
Yes, this blog post is a bit of a joke! It is not about the model itself, it’s actually a brief introduction to fine-tuning, which allows you to “tune” a smaller model to perform like a big one on a specific task (this part is very important.)
Fine-tuning Cheater-7B on a select 11 problems demonstrates that you don't need vast datasets to achieve significant improvements. This little giant not only excelled in familiar territory but also showed promising signs of learning from new, unseen challenges.
Beyond Cheating
Yes, Cheater-7B got a head start by "cheating" on the test! We fine-tuned it on 11/14 test cases in our leaderboard (the one we compare models on) - this happens more often than you think in the real world (often unconsciously).
But the real story here is the power of fine-tuning - because our model turned out to be better than the base model (the model we fine-tuned) in some of the unseen test cases as well! Clearly, it did pick up some Julia knowledge along the way.
Fine-tuning 101
What Is It?
Fine-tuning a model involves adjusting a pre-trained machine learning model's parameters so it can better perform on a specific task, effectively leveraging the model's learned knowledge (probability distribution of the next token) and adapting it to new, related challenges with a relatively small dataset.
Why Fine-Tuning Should Be Your New Best Friend
Fine-tuning stands out for specific tasks (ie, narrow domains) that demand efficiency, and privacy. It's akin to sharpening your tools to ensure they cut cleaner and faster, all while keeping the costs astonishingly low.
Once you build your Generative AI system, sooner or later you will have to route some of the simple requests to smaller fine-tuned models as part of the optimization process. Everyone does that, even the big players.
Understanding the Limits of Fine-Tuning
While fine-tuning can transform a general AI model into a specialist, it's not a silver bullet. This process excels at refining a model's existing knowledge to perform specific tasks (eg, adjusting the format or style, embedding certain prompts or examples) with greater accuracy or up-weighting/surfacing certain knowledge (eg, Julia) to be used more.
However, it does have many limitations. It's not very effective for tasks that require the model to learn entirely new information or skills from scratch. For such challenges, you might need to incorporate additional learning methods, like Retrieval Augmented Generation (RAG), to supplement the model's capabilities. In essence, fine-tuning adjusts the focus of the lens but doesn't replace the lens altogether.
Getting Started with Fine-Tuning: Easier Than You Think
Diving into fine-tuning is more accessible than ever, thanks to user-friendly tools like Axolotl. This approach not only simplifies the process but also opens the door to a collaborative effort in building specialized, efficient AI models for specific needs.
You need very little data to get started - we used just 11 test cases to get started.
You can find all the required resources and recipes here.
The Cheater-7B Experiment: Fast, Affordable, Enlightening
The journey of creating Cheater-7B was a lesson in efficiency itself: just 1 hour of processing on a cloud GPU, with an investment that didn't even hit the half-dollar mark. This experiment underscores the practicality and accessibility of fine-tuning for AI enthusiasts and professionals alike.
Getting Started with Fine-Tuning Data
Your first step in fine-tuning is to gather examples, specifically AI conversations that align with the skills you're aiming to enhance (eg, good Julia conversations/exchanges). To save these conversations for later use, you can employ a helpful function from the PromptingTools package save_conversation (saves a conversation to JSON).
If you're looking for a communal space to store and share these conversations, consider contributing to an open-source project. Open a pull request at Julia-LLM-Leaderboard's Julia Conversations to add your valuable data to the collective repository. This folder also shows example code snippets on how to save your conversations from PromptingTools.
I hope to write a detailed walkthrough of the process soon, but for now, you can find all the required resources and recipes here.
Conclusion
Cheater-7B's story is more than a quirky anecdote; it's a compelling illustration of how fine-tuning can unlock the potential of AI models, transforming them into task-specific powerhouses. As we continue to explore and share our experiences, the possibilities for innovation and improvement in AI are boundless.
Got a cool idea or breakthrough with your fine-tuning experiments? Share it in the generative-ai channel on Julia Slack and inspire the community with your innovation!
Resources
Discover Axolotl: Axolotl
Explore the Julia LLM Leaderboard: Julia LLM Leaderboard
Resources to Train Your Cheater-7B: Cheater-7B experiment.
Saving Conversations with PromptingTools: Julia Conversations folder.
Trained Cheater-7B Model: Cheater-7B Model
Extra Questions
Is it expensive? The process of fine-tuning Cheater-7B was surprisingly affordable, costing less than half a dollar. By renting a cloud GPU from Jarvislabs.io and opting for a spot instance outside of peak hours, the entire fine-tuning operation on an RTX A5000 was completed in about an hour for just $0.39.
How was Cheater-7b trained? Is it difficult? Training Cheater-7B was streamlined and accessible, thanks to the Axolotl tool.
Axolotl simplifies the fine-tuning process, making it approachable even for those new to machine learning. With just a few commands in the CLI, a configuration YAML file, and the selected dataset, Cheater-7B was fine-tuned efficiently. This ease of use demystifies the process, making advanced AI techniques available to a broader audience. See the example configuration in the Resources section.
Where did you get the data? The data for fine-tuning Cheater-7B came from the Julia LLM Leaderboard, focusing on solutions that demonstrated excellence and diversity. Specifically, we took the top 50 solutions that scored full points (100 points) for 11 out of the 14 test cases across different prompts.
The associated code is available in the Resources section.
Can I try/use the model? Yes, of course. Download the LORA adapter or the quantized version from here. I'd recommend using
llama.cpporLlama.jlto run it.Did we not just memorize the results?
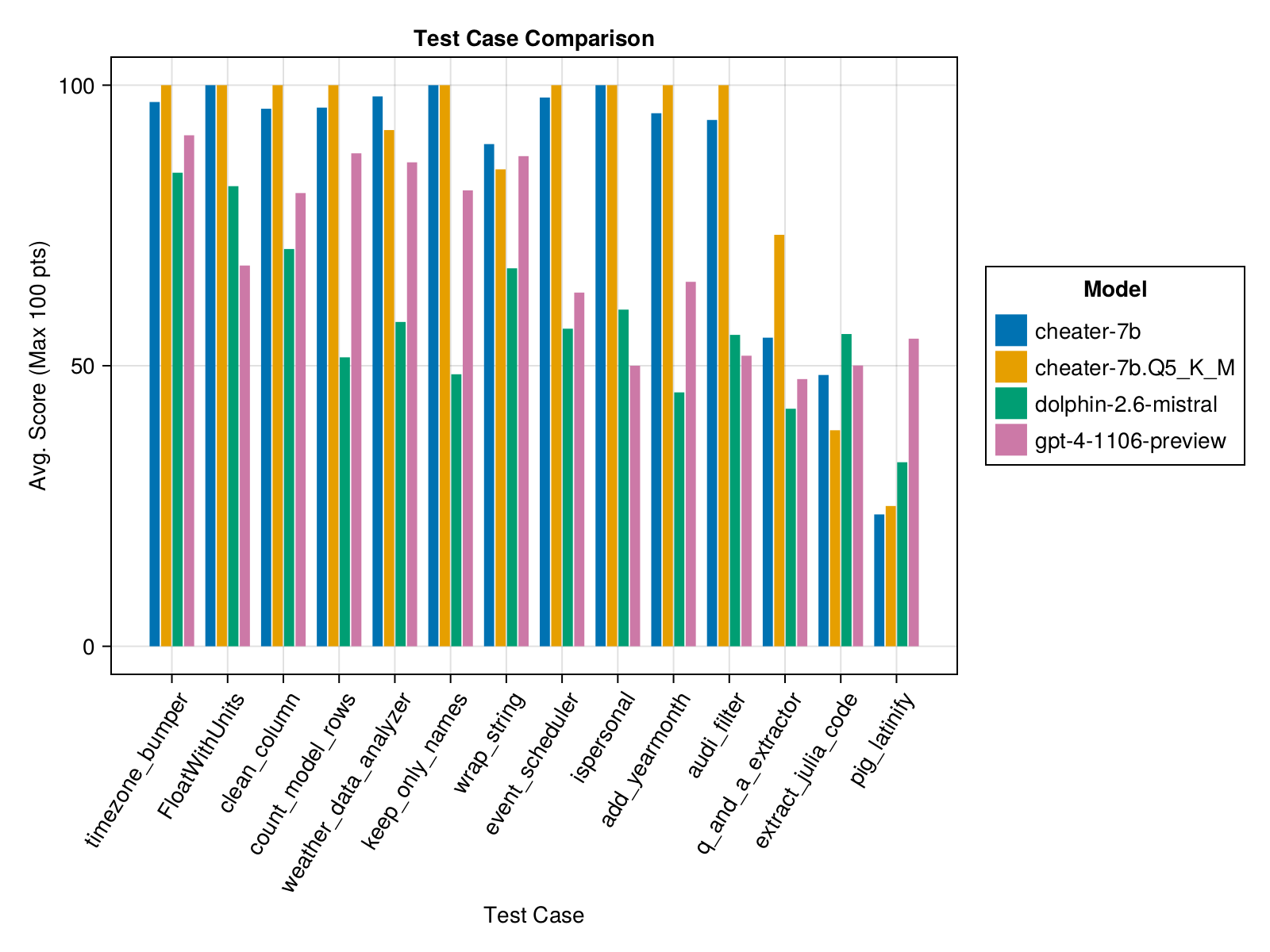
Well, partially! See below the performance of each model (and GPT4 for comparison) on various test cases.
We fine-tuned our model on the first 11 test cases. It has never seen any of the last 3 test cases:
q_and_a_extractor,pig_latinify, andextra_julia_code. These are the hardest test cases in our leaderboard and you can see that even GPT4 struggles to produce "executable" code (>50 points) for these.The 11 training cases didn't teach our model much about
pig_latinify(requires knowledge of multi-threading and associated libraries) andextract_julia_code(requires large models because there can be multiple nested levels of triple backticks and strings in the inputs, which tips up most models).However, the performance on
q_and_a_extractorhas increased significantly compared to both GPT4 and the base model! It's likely because the model learned how to do Regex operations in Julia and learned to navigate the return types better.