Stop Waiting for Test Data: Accelerate Your Experiments with LLM-Generated Datasets
26 November 2024
TL;DR
Ever had a brilliant idea but got stuck waiting for test data? Learn how to generate high-quality, realistic test data in just 5-10 minutes using LLMs and Julia. We'll walk through a complete example of generating customer records for fuzzy matching experiments.
The Challenge of Test Data
Recently, I wanted to experiment with fuzzy matching entities in databases using RAG (Retrieval-Augmented Generation). While RAG is famous for powering knowledge chatbots, I saw potential for matching similar records across databases. Think finding "John Smith" across systems where he might be listed as "J. Smith" or "Johnny Smith."
Traditional approaches like random data generators often create unrealistic data, while manual creation takes forever. What we need is data that looks and feels real, with natural variations and inconsistencies.
LLMs to the Rescue
This is where LLMs shine. Unlike traditional random generators, LLMs understand context and can generate realistic variations. Using Julia and the PromptingTools package, we can go from idea to usable test data in minutes.
The key advantages of LLM-generated data:
Natural variations in naming patterns (Bob vs Robert)
Contextually appropriate email addresses matching names
Realistic address formats and locations
Coherent relationships between fields
Implementing the Generation
All you need is to have a clarity on the data you need for your task. Eg, for a fuzzy matching of contacts, you could have:
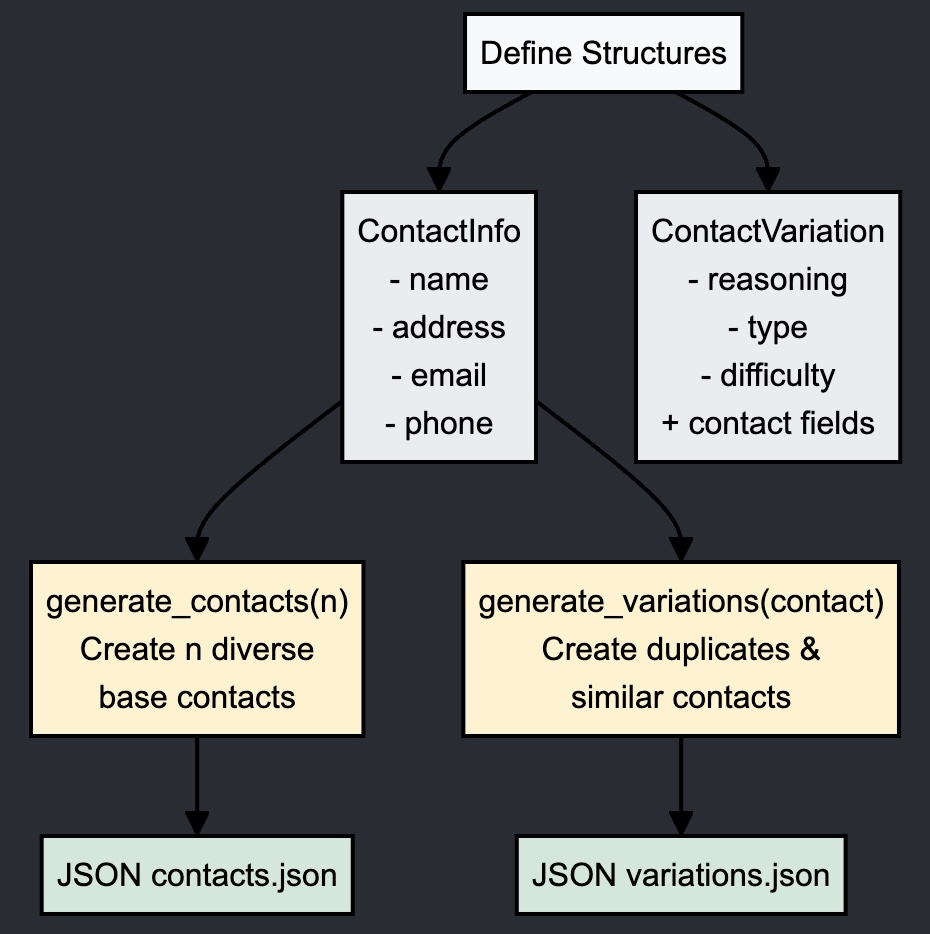
Base.@kwdef struct ContactInfo
full_name::String
address::String
city::String
state::String = "NY"
email::String
phone::String
endAnd to have some labeled data to test various approaches, you could have:
@enum JudgementType DUPLICATE NOTDUPLICATE
@enum Difficulty EASY MEDIUM HARD
Base.@kwdef struct ContactVariation
reasoning::String
type::JudgementType
difficulty::Difficulty
full_name::String
address::String
city::String
state::String = "NY"
email::String
phone::String
endThe best part is that all this can be dictated to your IDE that will efficiently generate the first draft of this flow for you.
Smart Generation Strategies
Here are a few tips to get the most out of LLM data generation:
One-Shot Generation: Always generate all your data in one go. Multiple calls often lead to repetitive data. You'll hit a natural limit of how many tokens models want to output (asking for 1000 items will get you only a tiny fraction). If you need more than 50, look for seeding strategies.
Smart Seeding: Need more variety? Instead of asking for 1000 random profiles, try this:
Generate 10 different careers
Generate 10 different hobbies
Generate 10 different locations
Now you have 1000 unique combinations to seed your generations! Create a prompt that uses these seeds as placeholders and generate the corresponding data points.
Cache and Temperature:
If you need multiple generations, vary the temperature slightly (by 0.001) between calls to avoid hitting the prompt cache. Or use multi-sampling (API kwarg
nin OpenAI API).In general, higher temperatures (0.7-0.9) generally work better for diverse data and varying temperature can enhance diversity.
Scale Up:
Need even more data? Use billion personas dataset as seed material
Break your generation into themed chunks: "generate 50 tech professionals", "generate 50 healthcare workers", etc.
Reuse past generations as seeds for new generations/variations
Let Your IDE Help:
Use your IDE's AI capabilities with PromptingTools cheatsheet (see the repo, folder
llm-cheatsheets/)Dictate your requirements to generate base data and task-specific variations
Let the LLM generate the initial code, then make minor edits
You will have your data in no time!
Quick Start Guide
Want to try this yourself? Here's the 5-minute path to generating test data using PromptingTools.jl:
File types_and_utils.jl Helpful types to steer the generation. We save them into a separate file to be able to lead them in our work later on.
## Key types
Base.@kwdef struct ContactInfo
full_name::String
address::String
city::String
state::String = "NY"
email::String
phone::String
end
@enum JudgementType DUPLICATE NOTDUPLICATE
@enum Difficulty EASY MEDIUM HARD
Base.@kwdef struct ContactVariation
reasoning::String
type::JudgementType
difficulty::Difficulty
full_name::String
address::String
city::String
state::String = "NY"
email::String
phone::String
end
Base.show(io::IO, contact::Union{ContactInfo,ContactVariation}) = dump(io, contact; maxdepth=1)
## Utility functions
"Converts a ContactInfo or ContactVariation to a string to pass to a LLM"
function format_contact(contact)
"Contact: $(contact.full_name)\nAddress: $(contact.address)\nCity: $(contact.city)\nState: $(contact.state)\nEmail: $(contact.email)\nPhone: $(contact.phone)"
endFile: generate_contacts.jl
Now, let's generate some contacts:
uusing PromptingTools
const PT = PromptingTools
using JSON3
using Dates
include("types_and_utils.jl")
# Function to generate diverse contact details
function generate_contacts(n::Int)
prompt = """Generate $n diverse contact details for people in New York state.
Include variations in names (titles Dr., Mr., Mrs., suffixes like Jr, Sr, III), some short, some long, some with middle names, some with titles.
Produce diverse addresses, different NY cities, and valid-looking emails and phone numbers."""
response = aiextract(
prompt;
return_type=PT.ItemsExtract{ContactInfo},
model="gpt4o",
json_mode=true,
strict=true
)
# No need for manual JSON parsing since aiextract handles it
return response.content.items
end
# Function to generate variations
function generate_variations(contact::ContactInfo; n_duplicates::Int=10, n_similar::Int=10)
prompt = """Generate $(n_duplicates + n_similar) contact variations.
Original contact:
{
"full_name": "$(contact.full_name)",
"address": "$(contact.address)",
"city": "$(contact.city)",
"state": "NY",
"email": "$(contact.email)",
"telephone": "$(contact.telephone)"
}
Provide a short reasoning for each variation to explain why it is a duplicate or not duplicate. It must be very clear.
First $(n_duplicates) entries should be duplicates of different levels of difficulty, eg, from simple typos and formatting differences to more complex variations.
Last $(n_similar) entries should be different people with similar attributes to the original contact, but they MUST BE A DIFFERENT person.
Provide contacts with different level of difficulty to notice that they are a different person.
"""
response = aiextract(
prompt;
return_type=PT.ItemsExtract{ContactVariation},
model="gpt4o",
json_mode=true,
strict=true
)
return response.content.items
end
# Generate initial contacts
contacts = generate_contacts(50)
JSON3.write("rag_dedupe/contacts.json", unique(contacts))
## Pick one contact and generate variations for it
contact_idx = 1 # use more for testing!
selected_contact = contacts[contact_idx]
variations = generate_variations(selected_contact, n_duplicates=10, n_similar=10)
JSON3.write("rag_dedupe/contact_variations.json", variations)